|
Анализ данных в корпоративных сетях
Корпоративное хранилище данных содержит обширную информацию обо всех сторонах деятельности предприятия, интегрированную из множества оперативных источников, - как детализированные данные с разбивкой по заданным промежуткам времени, так и агрегированную информацию. Общий ее объем может исчисляться терабайтами и более высокими единицами.
Для анализа таких информационных массивов в SQL Server 7.0 содержится особый механизм OLAP Services, содержащий OLAP-сервер и службу PivotTable. На OLAP-сервер возлагается задача подготовки и управления информационным кубом для передачи многомерных данных к сервису PivotTable, который, в свою очередь, предоставляет эту информацию клиентам через объекты ActiveX Data Objects (Multidimensional) - ADO MD или через интерфейс OLE DB for OLAP (см. Рис. 37.).
Рис. 37. Архитектура служб OLAP для Microsoft SQL Server 7.0
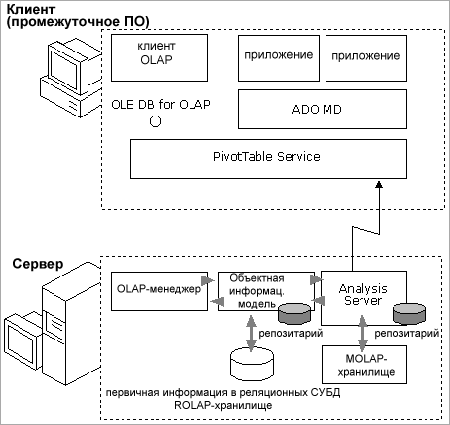
Многомерный информационный куб может физически располагаться в одном или нескольких контейнерах хранения, именуемых разделами (partitions). Каждый такой раздел может содержать данные, полученные из различных источников, и размещаться в любом месте корпоративной сети. Обновление информации в кубе производится по разделам независимо друг от друга. Разделы позволяют администратору, например, физически разделять разнородные данные и производить их автономную обработку.
Однако при использовании хранилищ данных часто приходится решать целый ряд проблем. Первая - "пустоты" (логически не заполняемые ячейки в кубе). Например, в базе данных по региональным представителям и регионам это будут ячейки для регионов, на которые не распространяется деятельность конкретного представителя. Для решения данной проблемы в OLAP Services предусмотрен запрет на выделение физического пространства до фактического заполнения конкретной ячейки, а также применение технологий сжатия данных и интеллектуального алгоритма при подготовке итоговых агрегатов.
Другая проблема - это борьба с взрывным ростом объема данных. Для ее решения предлагается специальный мастер Design Storage Wizard, позволяющий выбрать способ сохранения информации в кубе или разделах, а также возможность создавать агрегаты, оптимизированные по затратам дисковой памяти и времени реакции. С помощью мастера Usage-Based Optimization Wizard можно добиться оптимальной производительности с учетом предыстории запросов к кубу.
Любые изменения, вносимые через OLAP Manager или связанные исходные данные, переносятся в куб. Существует три способа для его обработки: полный (полная реструктуризация), дифференциальный (при внесении новых данных создается дополнительный раздел и пересчитываются агрегаты), обновление (внесение исходных данных без изменения структуры куба).
Используя Microsoft Visual Basic или Visual C++, а также COM-интерфейсы, можно расширить встроенный список функций, добавив пользовательские инструменты для анализа данных в OLAP-приложениях. В этом случае доступ к объектной модели сервера осуществляется через объекты Decision Support Objects (DSO) и интерфейс OLAP Add-In Manager. Разработана спецификация MDX (MultiDimensional eXtensions for SQL) для организации запросов к многомерным кубам.
В OLAP Services предусмотрены специальные меры для защиты доступа к информации на уровне данных и операций. Механизм аутентификации обслуживается через Security Support Provider Interface (SSPI), который предоставляет три уровня доступа к объектам базы данных и кубам, а функции проверки передает интегрированной системе защиты Windows NT. Предусмотрен механизм управления ролями, позволяющий присвоить соответствующие права отдельным пользователям и группам.
Механизм PivotTable является клиентом службы OLAP Service и служит для организации online-доступа к OLAP-данным. С его помощью полученные данные сохраняются локально на компьютере клиента и анализируются в offline-режиме. Однако в обработке при этом участвует единственный локальный раздел куба, а средства обработки агрегатов не используются.
Таким образом, модель данных OLAP существенно упрощает формулирование сложных запросов, фильтрацию и классификацию данных, легко позволяет изменять степень детализации результатов. Она предлагает естественный, интуитивно понятный метод навигации и высокоэффективного анализа при принятии решений.
Версия SQL Server 2000 дает новый импульс в развитии технологии анализа данных в хранилищах. В ней реализована спецификация OLE DB for Data Mining, являющаяся открытым интерфейсом для эффективного интегрирования технологии поиска закономерностей (data mining) в составе прикладных разработок стратегического планирования и электронной торговли. Эта технология отвечает за поиск внутренних связей в данных и составление прогнозов. Практически доступная для пользователей, не являющихся экспертами в области математической статистики и теории анализа, она значительно облегчает изучение и поиск информации в базах данных больших объемов.
В результате ее применения можно получить список правил, которым удовлетворяют имеющиеся данные, дерево возможных решений, модель регрессии или таблицу ассоциативных утверждений. Можно прогнозировать итоговые данные, находить неизвестные параметры. Среди основных направлений использования технологии Data Mining можно назвать: расчетное моделирование (классификацию), сегментацию (кластеризацию), выработку ассоциативной модели, анализ составляющих правил и оценку отклонений, выявление причинно-следственных связей.
Для применения OLE DB for DM в составе прикладных систем вводится новый виртуальный объект Data Mining Model (DMM). Напоминающий обычные таблицы СУБД, доступные через SQL-команды, этот объект, тем не менее, рассматривается как особый тип таблиц. Поступающие в БД новые данные сначала обрабатываются по DM-алгоритму, и полученные абстрактные результаты попадают в таблицу. Каждая запись в DMM выражает определенное соотношение между связанными исходными данными и именуется как case (ситуация). Содержимое объекта DMM можно рассматривать как своеобразную "таблицу истинности" ("truth table"), в которой учитываются все возможные ситуации с учетом используемого алгоритма оценки. Поэтому прежде чем с помощью DMM можно будет реально получать обоснованные статистические предсказания, его нужно как следует изучить, и вопросу обучения уделяется очень серьезное внимание.
Таким образом, благодаря внедрению новейших технологий Microsoft средства анализа и прогноза сегодня становятся реальным инструментом, способным играть решающую роль в повышении эффективности использования баз данных. Стратегия Microsoft направлена на то, чтобы эти технологии сделать доступными для массового рынка, предложив единые для отрасли интерфейсы и способы представления данных.
|
