
Процессор запросов Microsoft SQL Server
7.0
 Гетц Грефе, Джим Эвел и
Сезар Галиндо-Легариа
Гетц Грефе, Джим Эвел и
Сезар Галиндо-Легариа
Информация,
содержащаяся в этом документе, представляет текущую точку зрения корпорации Microsoft
на обсуждаемые вопросы на
момент публикации. Поскольку
Microsoft должна реагировать
на изменяющиеся условия на рынке, документ не следует рассматривать как
обязательство со стороны Microsoft; корпорация
Microsoft не может
гарантировать, что вся представленная информация сохранит точность после даты
публикации.
Настоящий
документ предназначен только для информационных целей. MICROSOFT НЕ ДАЕТ В ЭТОМ ДОКУМЕНТЕ НИКАКИХ
ЯВНЫХ ИЛИ ПОДРАЗУМЕВАЕМЫХ ГАРАНТИЙ.
©1998 Microsoft Corporation. Все права защищены.
Microsoft, BackOffice, логотип
BackOffice, Visual FoxPro, Windows, Windows NT
и Visual Studio 97 представляют
собой зарегистрированные торговые марки либо торговые марки корпорации
Microsoft в США и/или других
странах.
Другие
упоминаемые здесь торговые марки и названия продуктов являются собственностью
соответствующих владельцев.
Microsoft Part Number: 098-80763
Введение...................................................................................................................................................................
Что такое процессор запросов?..................................................................................................................
Типы оптимизаторов запросов...................................................................................................................
Синтаксические оптимизаторы запросов........................................................................................
Затратные оптимизаторы запросов..................................................................................................
Цели разработки Microsoft SQL Server 7.0..................................................................................................
Требования к продукту.................................................................................................................................
Легкость использования........................................................................................................................
Масштабируемость и надежность.....................................................................................................
Создание хранилищ данных...............................................................................................................
Лидерство и инновации.........................................................................................................................
Улучшения в процессоре запросов............................................................................................................
Больше вариантов выбора для оптимизатора
запросов.............................................................
Улучшения в выполнении запросов..................................................................................................
Параллельное выполнение запросов................................................................................................
Оптимизация для запросов хранилища данных............................................................................
Минимальная нагрузка на администратора баз
данных...........................................................
Улучшенные инструменты диагностики и
исправления проблемных запросов..................
Выполнение запросов.........................................................................................................................................
Дисковый ввод-вывод....................................................................................................................................
Ввод-вывод с последовательным и произвольным
доступом....................................................
Ввод-вывод больших объемов данных.............................................................................................
Сканирование с опережающим чтением..........................................................................................
Подсказки для предварительной выборки.......................................................................................
Улучшения сортировки.................................................................................................................................
Соединение слиянием, соединение с
хэшированием и группы хэширования...............................
Соединения слиянием............................................................................................................................
Соединения с хэшированием...............................................................................................................
Группы хэширования..........................................................................................................................
Пересечения по индексам...........................................................................................................................
Соединения по индексам............................................................................................................................
Параллельные планы..................................................................................................................................
Факторы, влияющие на параллельность.......................................................................................
Другие параллельные операции..............................................................................................................
Оптимизация запросов.....................................................................................................................................
Многофазная оптимизация........................................................................................................................
Автоматические параметры......................................................................................................................
Транзитивные предикаты...........................................................................................................................
Вложенные запросы....................................................................................................................................
Перемещение предложений GROUP BY.................................................................................................
Представления с разбиением....................................................................................................................
Запросы типа “звезда”................................................................................................................................
Декартовы произведения и составные индексы..........................................................................
Сокращение полусоединений и пересечение по
индексам......................................................
Комбинированные методы................................................................................................................
Оптимизированное обновление................................................................................................................
Распределенные запросы.................................................................................................................................
Гетерогенные запросы................................................................................................................................
Прозрачные запросы...................................................................................................................................
Работа с запросами............................................................................................................................................
Query Analyzer...............................................................................................................................................
Query Governor...............................................................................................................................................
SQL Server Profiler.........................................................................................................................................
Мастер настройки индекса........................................................................................................................
Автоматическое построение и обновление
статистики....................................................................
Заключение...........................................................................................................................................................
Поиск дополнительной информации.........................................................................................................
Дополнительные ссылки............................................................................................................................
Microsoft® SQL Server™ версии 7.0 опирается на надежный фундамент, созданный Microsoft SQL Server 6.5, и определяет направление развития
продуктов Microsoft для работы с базами данных. SQL Server 7.0 включает значительные нововведения,
направленные на удовлетворение потребностей и пожеланий клиентов. Будучи лучшей системой управления реляционными базами
данных (РСУБД) для семейства операционных систем Microsoft
Windows®, SQL Server представляет собой удачное решение для широкого
спектра корпоративных пользователей и независимых разработчиков программ.
В этом документе описываются инновации и усовершенствования
в процессоре запросов SQL Server — компоненте сервера
баз данных, который воспринимает задания на языке SQL,
определяет способ выполнения команд и осуществляет выбранный план. SQL Server 7.0 предлагает значительные нововведения по
сравнению с другими коммерчески доступными продуктами РСУБД.
После краткого введения, посвященного роли процессора
запросов, их типам и элементам системы обработки запросов, в этом документе
будут рассмотрены следующие темы:
· Цели разработки Microsoft SQL Server 7.0
· Выполнение
запроса
· Оптимизация
запроса
· Распределенные
запросы
· Работа
с запросами
Чтобы получить дополнительную информацию, обратитесь к
документу “Механизм хранения Microsoft
SQL Server 7.0” (part number 098-80769).
Реляционная база данных состоит из множества частей, но в ее
сердце находятся два основных компонента — механизм хранения (storage engine) и процессор запросов (query processor). Механизм хранения осуществляет запись
данных на диск и чтение с него, а также поддерживает записи, управляет
одновременным доступом и ведет файлы протокола.
Процессор запросов воспринимает задания на языке SQL, определяет способ выполнения команд и осуществляет
выбранный план. Пользователь или программа
взаимодействуют с процессором запросов, а он, в свою очередь, обращается к
механизму хранения. Обратите внимание, что процессор
запросов изолирует пользователя от деталей выполнения запроса: пользователь задает
необходимый результат, а процессор запросов определяет, как этот результат
получить.
Обработка запросов состоит из двух основных фаз — оптимизации
запроса (query optimization) и выполнения
запроса (query execution).
Оптимизация запроса представляет собой процесс выбора
наиболее быстрого плана выполнения. В ходе этой фазы
процессор запросов решает:
· Какие
индексы следует использовать и использовать ли их вообще.
· В
каком порядке выполнять соединения.
· В
каком порядке применять ограничения, например, предложения WHERE.
· Какие
алгоритмы с большей вероятностью приведут к более высокой производительности,
учитывая полученную на основе статистических данных информацию о затратах.
Выполнение запроса — это процесс выполнения плана,
выбранного при оптимизации запроса. Кроме того,
возможности компонента выполнения определяют, какие методы доступны
оптимизатору запросов. Например, в SQL
Server реализовано как соединение с хэшированием, так и соединение
слиянием, так что оптимизатору запросов доступны оба этих алгоритма.
Оптимизатор запросов представляет собой мозг реляционной
системы управления базами данных. Хотя почти любую
задачу можно выполнить вручную, процессор запросов позволяет работать с
реляционной базой данных разумно и эффективно.
В качестве аналогии давайте представим себе две строительные
фирмы. Обе они получили задание построить дом. Он
должен иметь заданные размеры и заданное число окон, спален и ванных комнат,
включать кухню и т.д. Первая фирма начинает с
планирования. Она определяет, в каком порядке нужно
выполнять необходимые действия, какие этапы можно осуществлять параллельно,
какие этапы зависят от предыдущих и какие работники лучше всего подходят для
различных задач. Вторая строительная фирма не
занимается планированием. Ее сотрудники просто берут любые оказавшиеся под
рукой инструменты и начинают строить.
Если задача не окажется очень простой (а построить дом
обычно совсем не просто), то фирма, которая заранее спланировала работу, с
большей вероятностью закончит ее первой. По той же
причине реляционная база данных с изощренным оптимизатором запросов, скорее
всего, обеспечит более высокую скорость выполнения запросов (особенно сложных
запросов) по сравнению с базой данных, включающей простой оптимизатор.
Тип доступных инструментов также влияет на то, как быстро
можно выполнить задание, и в некоторой степени определяет, с какими заданиями
можно справиться. Например, самосвал очень полезен при
строительстве дома, но для очистки сада он будет совершенно неподходящим
инструментом. Точно так же реляционная база данных
должна не только включать развитый оптимизатор запросов, но и располагать
хорошими средствами их выполнения и выбирать удачные инструменты для конкретной
задачи.
В реляционных базах данных применяется два основных типа
оптимизаторов запросов — синтаксические и затратные.
Синтаксический оптимизатор запросов (syntax-based
query optimizer) создает процедурный план, обеспечивающий получение
ответа на SQL-запрос, однако
конкретный выбираемый им план зависит от точного синтаксиса и порядка
предложений в запросе. Синтаксический оптимизатор
запросов каждый раз выполняет один и тот же план, даже если число или состав
записей в базе данных меняется со временем. В отличие
от затратного оптимизатора, он не поддерживает и не рассматривает никакие
статистические характеристики базы данных.
Затратные оптимизаторы
запросов
Затратный оптимизатор запросов (cost-based
query optimizer) осуществляет выбор среди альтернативных планов,
обеспечивающих получение ответа на SQL-запрос. При этом он опирается на оценки затрат (число операций
ввода-вывода, процессорное время и т.д.), связанных с выполнением определенного
плана. Чтобы оценивать такие затраты, он ведет
статистику по числу и составу записей в таблицах и индексах. В
отличие от синтаксического оптимизатора, получаемый в результате план не
зависит от точного синтаксиса запроса или порядка предложений в нем.
Как в SQL Server 6.5, так и в SQL Server 7.0 реализован затратный оптимизатор запросов. SQL Server 7.0 отличается значительными улучшениями в
оптимизаторе, а также в механизме выполнения запросов.
Далее представлены общие цели разработки Microsoft
SQL Server 7.0 и конкретные задачи, связанные с процессором запросов.
При разработке продукта ставилась задача обеспечить легкость
его использования, масштабируемость, надежность и полную поддержку создания
хранилищ данных.
Покупатели хотят получить решения конкретных проблем бизнеса,
однако многие решения на рынке баз данных только увеличивают сложность и
затраты. Стратегия Microsoft
состоит в том, чтобы сделать SQL Server лучшей базой
данных для создания, управления и развертывания бизнес-приложений. Это значит, что необходимо дать разработчикам быструю и
простую модель программирования, сделать возможным выполнение стандартных
операций без помощи администратора баз данных и предложить развитые инструменты
для решения более сложных задач.
Клиенты вкладывают средства в системы управления базами
данных, разрабатывая приложения для конкретной системы и обучая сотрудников,
осуществляющих их развертывание и управление. Эти инвестиции необходимо
защищать. По мере роста бизнеса база данных также должна расти, чтобы
обрабатывать больше данных, транзакций и пользователей. Кроме
того, клиенты хотят защитить свои инвестиции при масштабировании приложений баз
данных вниз (приложения для мобильных компьютеров) или в ширину (к филиалам
офисов).
Удовлетворяя эти потребности, Microsoft предлагает
единый механизм управления базами данных, который допускает масштабирование от
мобильного блокнотного компьютера с операционной системой Windows
95 или Windows 98 до терабайтных
симметрично-многопроцессорных кластеров под Windows NT® Server
Enterprise Edition. Все эти системы обеспечивают безопасность и
надежность, необходимую для ответственных бизнес-систем.
Системы обработки транзакций представляют собой ключевой
компонент корпоративной инфраструктуры баз данных, и SQL
Server 7.0 сохраняет лидерство по производительности и соотношению
“цена/производительность”, прочно установленное SQL Server 6.0
и SQL Server 6.5. В то же время компании
вкладывают значительные средства, чтобы улучшить анализа имеющихся данных. Цель SQL Server состоит в том,
чтобы снизить стоимость и сложность создания хранилищ данных, сделав эту
технологию доступной для более широкой аудитории.
SQL Server 7.0 включает много новых
возможностей, ориентированных на создание хранилищ данных, в том числе
параллельную обработку запросов, интегрированный сервер оперативной
аналитической обработки (OLAP) Plato, службу
преобразования данных Data Transformation Services (DTS),
репозитарий Microsoft Repository, интеграцию с системой
разработки Visual Studio® и интегрированную систему
тиражирования. Кроме того, процессор запросов был
усовершенствован для работы со сложными запросами и большими базами данных.
Инновации позволяют SQL Server 7.0 сохранять
лидирующие позиции в индустрии баз данных по нескольким из самых быстрорастущих
категорий приложений, включая электронную коммерцию, мобильные вычисления,
автоматизацию филиалов, приложения для работы с клиентами (line-of-business
applications) и создание хранилищ данных.
Предшествующие версии SQL Server обладали
превосходной производительностью при перемещениях от записи к записи и от
индекса к индексу, которые встречаются при небольших запросах и оперативной
обработке транзакций (OLTP — online transaction
processing). Цель разработки SQL Server 7.0 состояла
в том, чтобы усовершенствовать процессор запросов для использования в системах
поддержки принятия решений, обработки больших и сложных запросов, создания
хранилищ данных и OLAP. Вот некоторые из поставленных
при этом конкретных задач.
Предыдущие версии SQL Server обеспечивали
лишь ограниченные возможности оптимизации запросов. Например,
SQL Server 6.5 поддерживал только один метод соединения
— итерацию с вложенными циклами (nested loops iteration). В SQL Server 7.0 появились
алгоритмы соединения с хэшированием и соединения слиянием, которые
предоставляют оптимизатору больше вариантов решения и оказываются
предпочтительными в случае многочисленных и объемных запросов.
Вторая цель заключалась в том, чтобы улучшить выполнение
плана, когда он уже выбран. Здесь потенциальный выигрыш
в производительности могут обеспечить более быстрое сканирование,
усовершенствованная сортировка и поддержка большого объема памяти.
Сегодня все большее распространение получают
симметрично-многопроцессорные (SMP) машины, а также
наборы дисков с чередованием. В SQL
Server 6.5 был реализован параллельный ввод-вывод и параллельность между
запросами (выделение разных процессоров для разных запросов), однако он не мог
параллельно выполнять разные части одного запроса. SQL Server
7.0 разбивает один запрос на несколько подзадач и распределяет их по
нескольким процессорам для параллельного выполнения.
В приложениях хранилищ данных часто встречаются схемы и
запросы “звезда”. Такой запрос соединяет большую центральную таблицу,
называемую таблицей фактов, с одной или несколькими таблицами меньшего
размера, которые называются таблицами измерений. SQL
Server 7.0 автоматически распознает запросы этого типа и с учетом затрат
выбирает один из нескольких планов соединения “звезда”.
В настоящее время администраторов баз данных не хватает, и
их работа стоит очень дорого. Сводя к минимуму участие
администратора в выполнении стандартных операций, можно освободить его для
более сложных задач.
SQL Server 7.0 предлагает для
определения, диагностики и исправления проблемных запросов такие инструменты,
как Profiler, Query Analyzer и Мастер настройки
индексов. Эти утилиты позволяют администратору баз
данных найти источник проблемы, а во многих случаях предлагают также и пути ее
решения.
Выполнение запроса — это процесс осуществления плана,
выбранного в ходе оптимизации запроса. Здесь цель состоит в том, чтобы
выполнить план быстро, т.е. вернуть ответ пользователю (или, как чаще бывает,
запущенной пользователем программе) за наименьшее время. Это не то же самое,
что выполнение плана с наименьшим использованием ресурсов (процессора,
ввода-вывода и памяти). Например, параллельный запрос
почти всегда будет использовать больше ресурсов, чем непараллельный, однако он
часто оказывается предпочтительным, потому что быстрее возвращает пользователю
результат.
Набор реализованных методов выполнения запроса определяет
набор вариантов выбора, которые доступны оптимизатору запросов.
В этом документе выполнение запросов обсуждается до их оптимизации,
чтобы гарантировать полное понимание применяемых оптимизатором методов.
В основе эффективной обработки запросов лежит эффективность
передачи данных между дисками и памятью. SQL Server 7.0 включает
множество усовершенствований в области дискового ввода-вывода.
Операции ввода-вывода (чтение данных с диска) принадлежат к
числу наиболее дорогостоящих операций, выполняемых компьютерной системой. Существует два типа операций ввода-вывода: при вводе-выводе
с последовательным доступом данные читаются в том порядке, как они хранятся на
диске, а ввод-вывод с произвольным доступом позволяет читать их в любом
порядке, перепрыгивая с одного места диска на другое. Произвольный
доступ может приводить к более высоким затратам, чем последовательный, особенно
при чтении больших объемов данных.
Microsoft SQL Server 7.0 поддерживает
дисковую структуру, которая сводит к минимуму ввод-вывод с произвольным
доступом и обеспечивает быстрое сканирование больших таблиц кучи (heap tables), т.е. таблиц без кластеризованного индекса, где
строки данных не хранятся в каком-либо определенном порядке. Эта
возможность важна для запросов поддержки принятия решений. Такое
сканирование в дисковом порядке можно применять также для кластеризованных и
некластеризованных индексов, если на последующих этапах обработки запроса
порядок сортировки индекса не требуется.
В предыдущих версиях SQL Server для
хранения данных использовалась цепочка страниц, так что каждая страница
содержала указатель на следующую страницу с данными для таблицы. Это приводило к вводу-выводу с произвольным доступом и не
позволяло осуществить опережающее чтение, поскольку серверу нужно было прочитать
страницу, чтобы узнать положение следующей.
SQL Server 7.0 применяет другой
подход. Карта размещения индекса (IAM
— Index Allocation Map) описывает расположение страниц,
используемых таблицей или индексом. IAM представляет
собой битовую карту страниц данных для конкретной таблицы, расположенных в
дисковом порядке. Чтобы получить все страницы, сервер
сканирует эту карту и определяет, какие страницы и в каком порядке необходимо
прочитать. Затем он может извлекать страницы с помощью ввода-вывода с последовательным
доступом, а также выполнять опережающее чтение.
Если сервер в состоянии просканировать индекс вместо того,
чтобы читать таблицу, он попытается это сделать. Это
полезно, если индекс является покрывающим, т.е. содержит все поля, необходимые
для удовлетворения запроса. Сервер может удовлетворить
запрос, прочитав индекс со структурой B-дерева в
дисковом порядке, а не в порядке сортировки, что приводит к последовательному
доступу и более высокой производительности.
В SQL Server 7.0 размер всех страниц
базы данных увеличился до 8 Кб, тогда как в предыдущих версиях он составлял 2
Кб. Кроме того, теперь SQL Server читает данные блоками
по 64 Кб, а не по 16 Кб. Оба этих изменения повышают
производительность, позволяя серверу с помощью одного запроса ввода-вывода
читать больший объем данных. Это особенно важно для сверхбольших баз данных (VLDB — very large databases) и для
запросов поддержки принятия решений, где один запрос может требовать обработки
большого числа строк.
SQL Server 7.0 более полно
использует возможности дисковых наборов с чередованием, читая несколько блоков,
расположенных перед блоком, который действительно был необходим процессору
запросов. Это приводит к более быстрому сканированию
таблиц кучи и индексов со структурой B-дерева.
Сканирование в дисковом порядке увеличивает скорость доступа
к большим объемам данных. SQL Server 7.0 также ускоряет
выборку данных с помощью некластеризованного индекса.
При поиске данных с использованием некластеризованного
индекса сервер просматривает индекс и проверяет значения данных. Когда
конкретное значение обнаружено, индекс указывает адрес строки на диске. Традиционный подход состоит в том, чтобы немедленно дать
команду ввода-вывода для чтения этой строки по ее адресу. В
результате для чтения данных требуется по одной синхронной операции
ввода-вывода на строку, а в каждый момент времени для выполнения запроса
работает максимум один диск. Кроме того, при этом не используются преимущества
дисковых наборов с чередованием.
SQL Server 7.0 применяет другой
подход. Он продолжает просматривать некластеризованный индекс в поисках новых
указателей на записи. Собрав несколько таких
указателей, он передает механизму хранения подсказки для предвыборки (prefetch hints). Такие подсказки
сообщают механизму хранения, что эти конкретные записи вскоре понадобятся
процессору запросов. Теперь механизм хранения в
состоянии дать сразу несколько команд ввода-вывода, используя дисковые наборы с
чередованием для одновременного выполнения нескольких операций.
Алгоритмы сортировки образуют основу многих функций
процессора запросов, в том числе соединения слиянием, создания индексов,
агрегации потоков и т.д. Производительность сортировки в SQL
Server 7.0 резко возросла.
Каждая операция сортировки выполняется быстрее благодаря
множеству внутренних улучшений — упрощению сравнения, увеличению объема данных
в операциях ввода-вывода, асинхронному вводу-выводу и поддержке большой памяти. Кроме того, SQL Server 7.0 осуществляет
конвейеризацию данных между операцией сортировки и операциями запроса на ее
входе и выходе. Это позволяет избежать традиционно применявшихся в SQL Server фаз планирования запроса, которые требуют записи и
сканирования промежуточных рабочих таблиц.
В SQL Server 6.5 для соединения
использовалась итерация с вложенными циклами. Этот алгоритм превосходно
подходит для навигации от строки к строке, например, при переходе от записи для
заказа к трем или четырем входящим в него пунктам для продуктов. В то же время
он неэффективен при соединении большого числа записей, например, в типичных
запросах хранилища данных.
SQL Server 7.0 вводит три новых
метода соединения — соединение слиянием, соединение с хэшированием и группы
хэширования. Последний из них представляет собой значительное новшество,
которое не реализовано больше ни в одной реляционной базе данных.
Алгоритм соединения слиянием (merge join)
одновременно продвигается по двум отсортированным входным потокам, осуществляя
внутренние соединения, внешние соединения, полусоединения и логические операции
пересечения и объединения. Соединение слиянием
опирается на сканирование индексов со структурой B-дерева
в порядке сортировки и обычно является предпочтительным методом, если поля
соединения индексированы и если представленные в индексе столбцы покрывают
запрос.
Алгоритм соединения с хэшированием (hash
join) выполняет хэширование входных значений с помощью воспроизводимой
функции рандомизации, а затем проверяет значения из хэшированной таблицы в
поисках совпадений. Если объем входных данных меньше,
чем доступная память, то хэшированная таблица остается в памяти; для данных
большего объема применяются файлы переполнения на диске. Как
правило, хэширование представляет собой предпочтительный метод для больших
неиндексированных таблиц, в особенности для промежуточных результатов.
Операцию хеширования можно использовать для обработки
предложений GROUP BY, поиска уникальных значений (DISTINCT), пересечений, объединений, разностей, внутренних
соединений, внешних соединений и полусоединений. SQL Server
7.0 реализует все хорошо известные способы хэширования, в том числе
хэширование в памяти с оптимизацией кэширования, рекурсивное разбиение для
больших объемов памяти, гибридное хэширование,
фильтрацию с помощью битовых векторов и обращение ролей.
Группы хэширования (hash teams) —
это новаторская возможность SQL Server 7.0. Попросту
говоря, многие запросы включают несколько фаз выполнения, и оптимизатор
запросов должен использовать преимущества сходных операций на разных фазах
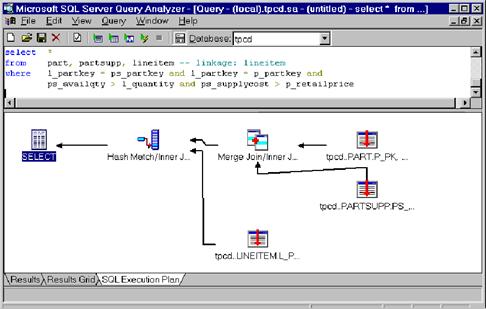
всюду, где это возможно. Например, пусть мы хотим узнать, сколько пунктов
заказа было введено для каждого артикула и каждого поставщика.
|
SELECT l_partkey, count (*)
FROM lineitem, part, partsupp
WHERE l_partkey = p_partkey and p_partkey = ps_partkey
GROUP BY l_partkey
|
В результате процессор
запросов генерирует следующий план выполнения.
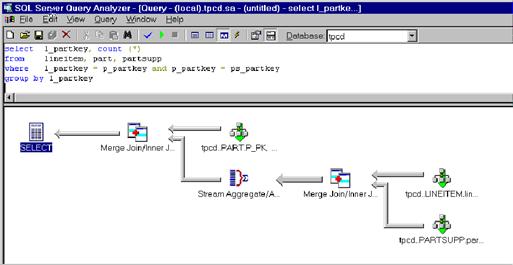
interest.bmp
Этот план запроса осуществляет внутреннее соединение
слиянием между таблицами lineitem и partsupp. Он определяет число
строк (агрегат потока), а затем соединяет результат с таблицей part. Запрос не требует ни одной
операции сортировки. Сначала он извлекает
отсортированные записи из таблиц lineitem и partsupp путем сканирования
индекса в порядке сортировки. В результате получаются
отсортированные входные данные для соединения слиянием, которое порождает
отсортированные данные для агрегации, а она, в свою очередь, обеспечивает
отсортированные входные данные для заключительного соединения слиянием.
Идея упорядочивания по интересу (interesting
ordering), т.е. устранения операций сортировки благодаря учету
упорядоченности промежуточных результатов при их движении от операции к
операции, сегодня реализована во всех основных процессорах запросов,
присутствующих на рынке. Однако SQL Server 7.0 делает
следующий шаг, применяя эту концепцию к соединениям с хэшированием. Давайте рассмотрим тот же самый запрос, но предположим, что
очень важный индекс для lineitems был удален, так что предыдущий план нужно было бы дополнить
дорогостоящей операцией сортировки по большой таблице lineitems.
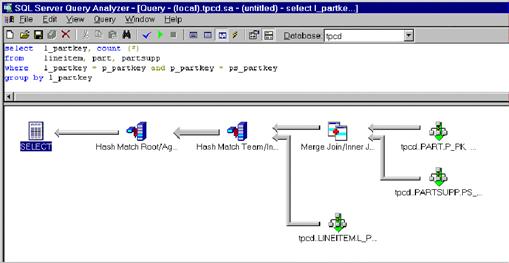
hashtm.bmp
В этом плане запроса вместо соединения слиянием применяется
соединение с хэшированием. Удаление индекса не затрагивает одну из операций
соединения слиянием, так что она остается очень быстрой. Две
операции хэширования снабжены специальными метками, показывающими, что они
представляют собой корень и член группы хэширования. Когда
данные перемещаются от соединения с хэшированием к операции группировки, она может воспользоваться результатами разбиения строк,
выполненного в ходе соединения с хэшированием. Это
устраняет потребность в файлах переполнения для одного из входов операции
группировки и тем самым снижает связанные с запросом затраты на ввод-вывод. В результате сервер быстрее обрабатывает сложные запросы.
Microsoft SQL Server 6.5 выбирал для
каждой таблицы один наиболее удачный индекс, даже если запрос включал несколько
предикатов. SQL Server 7.0 использует преимущества
нескольких индексов. Для этого он выбирает на основе каждого индекса небольшие
подмножества данных, а затем определяет пересечение двух подмножеств (т.е. возвращает
только те строки, которые удовлетворяют всем критериям).
Например, пусть вы хотите свести заказы по определенному
ряду идентификаторов заказчика, размещенные в определенный интервал времени.
|
SELECT count (*)
FROM orders
WHERE o_orderdate between '9/15/1992' and '10/15/1992' and
o_custkey between 100 and 200
|
SQL Server
7.0 в состоянии применить индексы по o_custkey
и по o_orderdate, а
затем получить пересечение по индексам (index intersection)
между двумя подмножествами с помощью алгоритма слияния. Этот
план выполнения обращается к двум индексам, причем оба они связаны с таблицей orders.
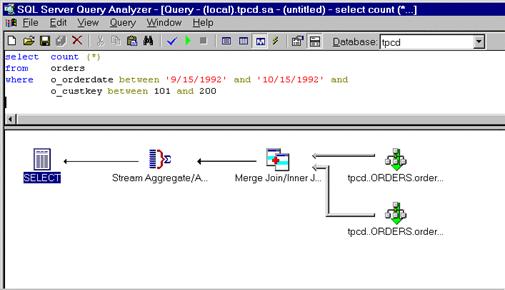
indxint.bmp
Соединения по индексам (index joins)
представляют собой вариант пересечений по индексам. Если
мы используем какой-то индекс и в нем самом доступны все необходимые для
запроса столбцы, то извлекать строку целиком не нужно. Такой индекс называется покрывающим
(covering), поскольку он покрывает, или содержит, все
требуемые для запроса столбцы.
Покрывающий индекс
представляет собой хорошо известный и распространенный прием, однако SQL Server 7.0 делает еще один шаг вперед, применяя его к
пересечению по индексам. Если ни один индекс сам по
себе не в состоянии покрыть запрос, но несколько индексов вместе могут это
сделать, то SQL Server рассмотрит план, основанный на
соединении этих индексов. Какая из альтернатив будет
выбрана, зависит от выполняемого оптимизатором запросов прогноза затрат.
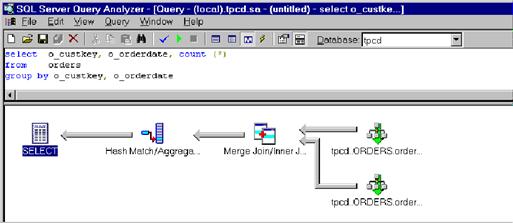
indxjoin.bmp
Microsoft SQL Server 7.0 вводит
понятие параллельности внутри запроса (intra-query
parallelism), т.е. возможности разбивать единый запрос на несколько
подзадач и распределять их для выполнения по нескольким процессорам в
симметрично-многопроцессорной машине.
Эта архитектура опирается на обобщенную операцию параллелизации,
на лету создающую несколько параллельных потоков. Все
операции (сканирование, сортировка и соединение) не знают о параллельности, но могут выполняться параллельно
просто потому, что они связаны с операцией параллелизации. Таким образом, мы
получаем “всеобщую параллельность”. Единственно исключение из этого принципа
касается параллельного обновления, поддержку которого Microsoft
включит в будущую версию SQL Server. Все
остальные операции (сканирование, сортировка,
соединение, группировка с помощью GROUP BY) осуществляются
параллельно.
SQL Server обнаруживает, что он
запущен на SMP-машине, и определяет наиболее подходящую
степень параллельности для каждого случая выполнения параллельного запроса. Учитывая текущую нагрузку и конфигурацию системы, SQL Server выясняет оптимальное число потоков и
распределяет между ними выполнение запроса. Начав
выполняться, запрос использует одно и то же число потоков вплоть до своего
завершения. SQL Server производит выбор оптимального
числа потоков каждый раз, когда параллельный план выполнения запроса
извлекается из кэша процедур. В результате может
оказаться, что одно выполнение какого-либо запроса использует лишь один поток,
а при другом выполнение того же самого запроса (в другое время) будут
использованы два или несколько потоков.
Автоматическое решение о том, применять ли параллельную
обработку запросов, в SQL Server 7.0 зависит от ответов
на следующие вопросы:
· Работает
ли SQL Server на компьютере с несколькими процессорами (SMP-машине)?
Параллельные запросы могут выполняться только на компьютерах, включающих более
одного процессора.
· Используете
ли вы SQL Server 7.0 версии Desktop, Standard или Enterprise? SQL Server
Desktop Edition поддерживает до двух процессоров, Standard Edition может
работать с четырьмя процессорами, а Enterprise Edition — с восемью.
· Сколько
активных пользователей в настоящее время обращаются к серверу? SQL Server
следит за использованием процессоров и корректирует степень параллельности в
момент запуска запроса. Если процессоры заняты, он выбирает более низкий
уровень параллельности.
· Достаточно
ли доступной памяти для параллельного выполнения запроса? Каждому запросу для
работы нужен определенный объем памяти, причем параллельные запросы требуют
больше памяти, чем непараллельные. Объем памяти, необходимый для выполнения
параллельного запроса, увеличивается с ростом степени параллельности. Если
требования параллельного плана к памяти невозможно удовлетворить при данной
степени параллельности, SQL Server автоматически уменьшает ее или совершенно
отказывается от параллельного плана запроса в условиях текущей нагрузки и
выполняет последовательный план.
· Каков
тип выполняемого запроса? Лучшими кандидатами для параллельного выполнения
будут запросы, использующие много тактов процессора. Примером таких задач могут
служить соединения больших таблиц, обширные агрегации или сортировки больших
наборов данных. Оказывается, что для простых запросов, которые часто
встречаются в приложениях обработки транзакций, необходимая при параллельном
выполнении дополнительная координация перевешивает потенциальный выигрыш в
производительности. Чтобы узнать, в каких запросах параллельность будет
полезна, а в каких нет, SQL Server сравнивает оценку затрат на выполнение
запроса с порогом затрат для параллелизации. Администраторы могут изменить
заданное по умолчанию значение порога, хотя делать это не рекомендуется.
· Достаточно
ли строк в данном конкретном потоке? Если оптимизатор запросов определяет, что
число строк в потоке слишком мало, он не включает в план параллельные
операторы. Выполнение последовательного плана позволяет избежать ситуации,
когда затраты на запуск, распределение и координацию потоков превысят выигрыш,
связанный с параллельным выполнением.
Помимо параллельных запросов, Microsoft SQL
Server 7.0 поддерживает параллельные нагрузки при использовании
нескольких клиентов, а также параллельное резервное копирование и
восстановление. Чтобы получить дополнительную
информацию, обратитесь к документам “Реализация больших
баз данных DSS с помощью Microsoft SQL
Server 7.0” (part number 098-81102) и “Тесты
производительности: высокая пропускная способность по
транзакциям во время онлайнового резервного копирования базы данных” (part number 098-812333).
Новаторский и современный оптимизатор запросов Microsoft SQL Server 7.0 обладает множеством граней.
Оптимизатор запросов SQL Server 7.0 в
процессе работы проходит несколько фаз. Прежде всего он
ищет простой, но осмысленный план выполнения, который позволяет удовлетворить
запрос. Если необходимое для этого плана время не
превышает порогового значения затрат (например,
составляет доли секунды), оптимизатор запросов не
беспокоится о поиске более эффективных планов. Это
предотвращает “переоптимизацию”, т.е. положение, когда оптимизатор тратит на
определение самого лучшего плана больше ресурсов, чем требуется для его
выполнения.
Если первый выбранный план требует больше времени, чем
значение порога затрат, то оптимизатор продолжит
рассмотрение других планов, каждый раз выбирая план с наименьшими затратами. Использование нескольких фаз обеспечивает хороший
компромисс между временем, необходимым для выбора самого эффективного плана, и
временем оптимизации для него.
Большинство процессоров запросов позволяет предварительно
скомпилировать и сохранить план выполнения, например, при компиляции хранимых
процедур. Предварительная компиляция увеличивает
эффективность, поскольку позволяет использовать план выполнения повторно. Такой план дает пользователю возможность передавать
переменные в качестве параметров плана. Реализованный в
Open Database Connectivity (ODBC) новый интерфейс подготовки
запросов для многократного выполнения также опирается на связанный с этим выигрыш
в эффективности.
Однако хранимые процедуры не применяются во многих
коммерческих приложениях и во всех разовых запросах, использующих вместо этого
динамический SQL. SQL Server 7.0 реализует новую
функцию, названную автоматическими параметрами (automatic
parameters). Она осуществляет кэширование планов, построенных для
динамического SQL, при этом преобразуя константы в
параметры. Это приводит к снижению затрат на компиляцию
и обеспечивает многие связанные с хранимыми процедурами преимущества в эффективности
даже для приложений, которые не используют такие процедуры.
Кроме того, в SQL Server 7.0 введена
полная поддержка параметризованных запросов с параметрами, задаваемыми
приложением, что характерно для ODBC, OLE DB и операций
“подготовить/выполнить” (prepare/execute).
Из школьного курса математики вы, возможно, помните свойство
транзитивности для чисел. Если A = B и B = C, то в соответствии со свойством транзитивности A = C. Это свойство можно применить к запросам.
|
SELECT *
FROM part, partsupp, lineitem
WHERE ps_partkey = l_partkey and l_partkey = p_partkey and
ps_availqty > l_quantity and ps_supplycost > p_retailprice
|
Поскольку как ps_partkey, так и p_partkey равны l_partkey, то ps_partkey должен быть равен p_partkey. Процессор событий может воспользоваться этим, выведя третий
предикат соединения (ps_partkey равен p_partkey). Например, в этом
запросе процессор сначала соединяет ключ части в таблице parts с ключом части в таблице partsupp, хотя этот конкретный предикат соединения вообще не был
указан в запросе. Процессор может это сделать благодаря
транзитивности предикатов.
nestqry.bmp
Связанные подзапросы представляют собой особую проблему для
любого процессора SQL-запросов. SQL
Server применяет к таким подзапросам некоторые специальные приемы и,
если возможно, разворачивает их в полусоединения. Преимущества
такого разворачивания связаны с тем, что оно позволяет применять все алгоритмы
соединения. Для больших запросов это означает, что
оптимизатор запросов в состоянии рассмотреть соединения с хэшированием или
соединения слиянием, а не использовать менее
эффективное соединение с вложенными циклами.
Стандарты SQL требуют выполнять
обработку запроса в определенном порядке:
1. Выполнить
предложения FROM и WHERE
2. Сократить
объем данных, используя предложение GROUP BY
3. Применить
все условия из предложения HAVING
Любой план, обеспечивающий
такие же результаты, тоже является корректным. Следовательно,
в некоторых запросах мы можем вычислить предложение GROUP BY раньше,
до выполнения одной или нескольких операций соединения из предложения WHERE, и тем самым снизить объем входных данных для
соединения и затраты на него. Такая операция называется
перемещением предложения GROUP BY. Вот пример.
|
SELECT c_name, c_custkey, count (*),
sum (l_tax)
FROM customer, orders, lineitem
WHERE c_custkey = o_custkey and o_orderkey = l_orderkey and
o_orderdate between '9/1/1994' and '12/31/1994'
GROUP BY c_name, c_custkey
|
Рассматривая предложение GROUP BY, процессор
запросов выясняет, что первичный ключ c_custkey определяет c_name, так что выполнять группировку по c_name в дополнение к c_custkey нет
необходимости. Затем оптимизатор обнаруживает, что
группировка по c_custkey и
o_custkey будет давать
одинаковые результаты. Поскольку таблица orders включает ключ клиента (o_custkey), процессор событий может осуществить
группировку по этому ключу сразу же, как только получит записи для таблицы orders, и до ее соединения с таблицей customer. Это становится
очевидным из следующего плана выполнения.
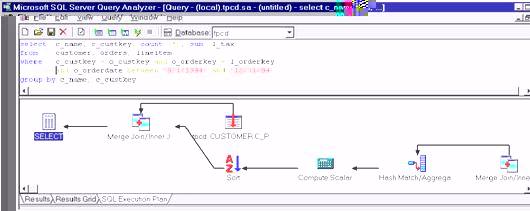
nestqry2
Сначала процессор запросов использует соединение слиянием
для таблицы orders (в
пределах указанного диапазона дат) и таблицы lineitem, чтобы получить все пункты заказов. Второй шаг — это агрегация с хэшированием, т.е. операция
группировки. На этом этапе SQL Server выполняет
агрегацию пунктов заказов на уровне ключа клиента, подсчитывая
их и вычисляя сумму значений l_tax. Затем SQL Server сортирует выходные
данные соединения с хэшированием и соединяет их с таблицей customer,
чтобы получить желаемый результат. Преимущество такого
плана запроса в том, что объем входных данных для заключительного соединения
существенно сокращается благодаря более ранней операции группировки.
Microsoft SQL Server 7.0 поддерживает
разбиение с использованием групп файлов. Такая
архитектура обеспечивает многие из преимуществ разбиения, в особенности
возможность администрирования на более низком уровне, чем целая база данных. В будущей версии SQL Server она
будет поддерживать разбиение на диске. Тем не менее для
больших запросов поддержки принятия решений SQL Server 7.0 реализует
представления с разбиением (partitioning views),
которые позволяют администратору баз данных создать несколько таблиц с
ограничениями — фактически, по одной таблице для каждого раздела. Затем эти таблицы снова логически объединяются с помощью
представления с разбиением. Мы рассмотрим это на
примере.
|
CREATE table
Sales96Q1 … constraint "Month between 1 and 3"
CREATE table Sales96Q2 … constraint "Month between 4 and 6"
…
CREATE view Sales96 as
SELECT * from Sales96Q1 union all
SELECT * from Sales96Q2 union all
…
|
Этот фрагмент на языке определения данных (DDL
— data definition language) создает четыре таблицы, по
одной для информации о продажах в каждом квартале, причем с каждой из них
связано соответствующее ограничение. Затем он строит
представление, вновь объединяющее все четыре таблицы. При
обновлении базы данных программисты должны знать о разбиении, однако для
запросов поддержки принятия решений оно оказывается прозрачным.
Получив запрос к представлению Sales96, процессор запросов автоматически находит и удаляет таблицы,
которые не удовлетворяют указанным в запросе ограничениям.
|
SELECT *
FROM Sales96 -- помните, это представление содержит четыре таблицы
WHERE s_date between '6/21/1996' and '9/21/1996'
|
Если вы дадите такой запрос, то
процессор запросов сгенерирует план, затрагивающий только две таблицы
представления (Sales96Q2 и Sales96Q3). Предложение WHERE противоречит
ограничениям для двух других таблиц, поэтому они не имеют значения для данного
запроса. Более того, для каждого отдельного квартала
могут использоваться разные пути доступа, например, сканирование по индексу для
нескольких дней второго квартала и сканирование по таблице для третьего
квартала. Это полезный метод повышения
производительности запросов, выбирающих из больших таблиц подмножества по
хорошо известным столбцам. Типичные примеры такой
ситуации касаются времени и места.
SQL Server обнаруживает все пустые
результаты, связанные с противоречием между ограничениями и критериями выбора. Даже если администратор не объявил представление,
оптимизатор распознает конфликт между критерием и ограничением и генерирует
соответствующий план.
Базы данных, разработанные для приложений поддержки принятия
решений и особенно для хранилищ и рынков данных, часто весьма сильно отличаются
по структуре таблиц от баз данных OLTP. Обычный подход
состоит в реализации схемы “звезда”. Этот тип схем базы данных был создан,
чтобы дать пользователям возможность интуитивного перемещения по содержащейся в
базе информации, а также обеспечить более высокую производительность для
больших разовых запросов.
Схема “звезда” исходит из наблюдения, что информацию можно
разделить на факты, т.е. численную информацию, составляющую ядро анализируемых
данных, и измерения, т.е. атрибуты фактов. Примерами
фактов служат продажи, единицы продукта, бюджеты и прогнозы, а примерами
измерений — географические данные, время, продукт и канал продаж. Пользователь часто выражают свои запросы словами “Я хочу рассмотреть эти факты по таким измерениям” или “Я хочу рассмотреть объем
продаж и число проданных единиц по каждому кварталу”.
Опираясь на это наблюдение,
схема “звезда” организует данные в виде центральной таблицы фактов и окружающих
ее таблиц измерений.
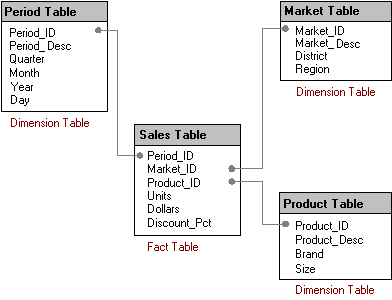
dts01.bmp
Microsoft SQL Server 7.0 включает
несколько способов оптимизации запросов к базе данных со схемой “звезда”. Процессор запросов автоматически распознает такие запросы и
может применять некоторые или все обсуждаемые здесь способы, а также различные
их сочетания. Важно понимать, что выбор применяемых
способов целиком определяется затратами и не требует никаких подсказок,
навязывающих такую оптимизацию.
Таблицы в схеме “звезда” содержат неравное число записей. Как правило, в таблице фактов записей гораздо больше, чем в
таблицах измерений. Это различие оказывается очень
важным для многих способов оптимизации запросов.
Прямолинейная стратегия выполнения состоит в том, чтобы
прочитать всю таблицу фактов и соединить ее по очереди с каждой из таблиц
измерений. Если в запросе не указано никаких условий
фильтрации, такой путь может оказаться разумным. В то
же время при наличии условий фильтрации оптимизация запросов типа “звезда”
позволяет избежать чтения всей таблицы фактов за счет полного использования
индексов.
Поскольку таблицы измерений обычно содержат меньше записей,
чем таблица фактов, может быть разумно вычислить их декартово произведение и
применить результат для поиска строк таблицы фактов в индексе с несколькими
столбцами.
Этот прием легче всего понять
при рассмотрении примера. Обратившись к предыдущей
схеме, давайте предположим, что таблица фактов, т.е. таблица sales, содержит 10
миллионов строк. Таблица period включает 20 строк, таблица market — 5,
а таблица product — 200 строк. Пользователь с помощью
клиентской утилиты генерирует следующий запрос.
|
SELECT sales.market_id, period.period_id,
sum(units), sum(dollars)
FROM sales, period, market
WHERE period.period_id = sales.period_id and
sales.market_id = market.market_id and
period.period_Desc in ('Period2','Period3','Period4','Period5')
and market.market_Desc in ('Market1','Market2')
GROUP BY sales.market_id, period.period_id
|
Простой подход сводится к соединению таблиц period и sales. Если допустить, что данные распределены равномерно, то
входной поток будет содержать 10 миллионов строк, а выходной — 4/20 от этой величины (4 периода из
20 возможных), или 2 миллиона строк. Эту
операцию можно выполнить с помощью соединения с хэшированием или соединения
слиянием, причем нам нужно будет прочитать все 10 миллионов строк таблицы
фактов или извлечь 2 миллиона строк путем поиска по индексу в зависимости от
того, какой способ будет связан с меньшими затратами. Затем
этот частичный результат соединяется с сокращенной таблицей market и дает 800 тысяч строк
выходных данных, которые в конце концов подвергаются агрегации.
Если для таблицы фактов существует многостолбцовый индекс,
например, по столбцам period_id и market_id, то можно обратиться к
стратегии, связанной с вычислением декартова произведения. Поскольку
из таблицы period выбраны
четыре строки, а из таблицы market — две, то декартово произведение будет содержать восемь
строк. Затем эти восемь комбинаций значений используются
для поиска 800 тысяч строк выходных данных. При таком
применении многостолбцовые индексы иногда называют индексами типа “звезда”.
Если соединения с таблицей фактов происходят по полям, не
входящим в составной индекс, то оптимизатор запросов может воспользоваться
другими индексами и сократить число строк, которые необходимо прочитать из
таблицы фактов. Для этого он осуществляет пересечение подходящих строк из
соединений с каждой таблицей измерений.
Например, если выбор производится по полям period_id и product_id, то оптимизатор не в состоянии применить составной индекс,
поскольку два интересующих нас поля (period_id и product_id) не входят в
ведущее подмножество индекса. Однако при наличии
отдельных одностолбцовых индексов по period_id и product_id
оптимизатор запросов может выбрать соединение между таблицами period и sales (извлекая 2 миллиона элементов индекса) и,
независимо от него, соединение между таблицами product и sales (извлекая
4 миллиона элементов индекса). В обоих случаях
соединение будет производиться с помощью индекса, так что эти два
предварительных соединения вычисляют набор идентификаторов записей для таблицы sales, но не полные ее строки. Перед
извлечением реальных строк из таблицы sales (не забывайте, что это самый дорогостоящий процесс) процессор запросов вычисляет пересечение двух множеств,
чтобы определить действительно подходящие строки. В этот промежуточный набор из
800 тысяч строк попадают только строки, удовлетворяющие условиям обоих
соединений, и в конечном счете только они действительно будут прочитаны из
таблицы sales.
В некоторых случаях сокращение полусоединений можно
применять в сочетании с декартовыми произведениями и составными индексами. Например, пусть необходимо произвести выбор из трех таблиц
измерений, причем две таблицы из трех образуют начальные поля составного
индекса, а третье измерение обладает отдельным индексом. В этом случае
оптимизатор запросов может использовать декартовы произведения, чтобы
удовлетворить первые два соединения, а затем удовлетворить третье с помощью
полусоединений и объединить полученные результаты.
На эффективность этих методов влияет несколько факторов. К
их числу относится соотношение размеров базовой таблицы и используемых
индексов, а также то, покрывает ли набор этих индексов все необходимые для
запроса столбцы, тем самым устраняя потребность в поиске строк в базовой
таблице. Оптимизатор запросов учитывает эти факторы,
выбирая план с наименьшими затратами.
Если связанные с таким планом затраты превышают порог затрат
для параллелизации, то все требуемые операции, включая сканирование,
соединение, пересечение и выборку строк, могут выполняться параллельно
несколькими потоками.
При обновлении строки в таблице необходимо обновить также
все индексы для нее. Для небольших изменений, например,
в операциях OLTP, индексы целесообразно обновлять по
одной строке одновременно с обновлением каждой строки базовой таблицы.
В то же время построчное обновление может оказаться
неэффективным для больших изменений, например, при обновлении хранилища данных,
поскольку оно приведет к большому объему операций ввода-вывода с произвольным
доступом к записям индекса. Более удачный подход
состоит в том, чтобы отложить обновление индексов до тех пор, пока не будут
обновлены все базовые таблицы, а затем осуществить предварительную сортировку
изменений для каждого индекса и одновременно внести в него все модификации. Это гарантирует, что SQL Server обратится
к каждой листовой странице индекса максимум один раз, а каждое B-дерево будет
пройдено последовательно.
Оптимизатор запросов выбирает такой подход, если он связан с
наименьшими затратами. Его преимущество в том, что он
обеспечивает более эффективное обновление больших хранилищ данных.
Наряду с этим оптимизатор запросов планирует операции
соединения, необходимые для реализации ограничений на целостность ссылок.
Опираясь на оценку затрат, он выбирает алгоритм вложенных циклов (по индексу),
соединения слиянием или соединения с хэшированием.
Помимо хранения и поиска локальных данных, Microsoft
SQL Server 7.0 также можно использовать в качестве шлюза для доступа ко
многим другим хранилищам данных — как к реляционным базам, так и к
нереляционным источникам данных.
SQL Server 7.0 выполняет
распределенные запросы, т.е. запросы, затрагивающие данные с двух или
нескольких серверов. Он поддерживает операции
извлечения, обновления и курсоры на нескольких серверах, а также гарантирует
семантику транзакций между узлами с помощью координатора распределенных
транзакций Microsoft Distributed Transaction Coordinator (MS
DTC). Кроме того, он обеспечивает систему безопасности для серверов.
Если какие-то удаленные серверы поддерживают индексы или SQL-запросы, то оптимизатор запросов SQL Server определяет наибольший запрос, который можно
направить каждому удаленному серверу. Другими словами,
оптимизатор обеспечивает максимально возможное сокращение данных на каждом из
серверов. Например, если к таблице из одного миллиона
строк направлен удаленный запрос с предложением WHERE или
агрегацией, которая возвращает всего 10 записей, то миллион строк
обрабатывается на удаленном сервере, а по сети передаются только итоговые 10
записей. Это снижает трафик в сети и общее время выполнения
запроса. Как правило, ближе к источнику данных
переносятся операции выбора, соединения и сортировки.
Распределенные запросы могут выполняться в гетерогенной
среде благодаря поддержке любых источников данных OLE DB или ODBC. Компакт-диск SQL Server 7.0 содержит
драйверы OLE DB для Oracle 7.x,
Oracle 8.x, Microsoft Excel, Microsoft Access, dBASE, Paradox и
системы разработки баз данных Microsoft Visual FoxPro®, а
также шлюз OBDC для доступа к другим реляционным базам
данных. Драйверы OLE DB Provider для
других серверных баз данных (IBM DB2, SYBASE и Informix) можно получить у независимых поставщиков.
Если удаленный сервер поддерживает синтаксис, не
соответствующий стандарту SQL, или если удаленный
источник данных использует какой-то другой язык запросов, то с помощью операции
OPENQUERY запрос можно передать ему без изменений
синтаксиса.
Наряду с улучшенными возможностями обработки запросов на
сервере Microsoft SQL Server 7.0 предлагает также усовершенствованные
инструменты для работы с запросами к базам данных.
SQL Server 7.0 включает утилиту Query Analyzer (анализатор запросов) — интерактивный
графический инструмент, позволяющий администратору или разработчику базы данных
писать запросы, выполнять одновременно несколько запросов, просматривать
результаты, анализировать план запроса и пользоваться справкой для повышения
его производительности. Опция SHOWPLAN
графически отображает методы извлечения данных, выбранные оптимизатором
запросов SQL Server, что очень полезно для понимания
характеристик производительности запроса. Кроме того,
анализатор запросов дает рекомендации по включению дополнительных индексов и
статистики по неиндексированным столбцам, которые могли бы помочь оптимизатору
более эффективно обрабатывать запрос. В частности,
анализатор показывает, отсутствие каких статистических данных заставляет
оптимизатор запросов строить догадки относительно селективности предикатов, а
также позволяет несколькими щелчками мыши создать такую статистику.
Затраты на запрос (query cost)
представляют собой оценку времени (в секундах), которое потребуется для
выполнения запроса при определенной аппаратной конфигурации. Для
различных конфигураций существовует сильная корреляция между величиной затрат и
необходимым временем выполнения запроса, однако единицы затрат не эквивалентны
секундам. Диспетчер запросов (query
governor) позволяет вам установить верхний предел затрат для запроса,
так что сервер не будет выполнять запросы, превышающие этот предел.
Диспетчер запросов опирается на оценку затрат, а не на
фактически затраченное время, поэтому он не вызывает
никаких накладных расходов во время выполнения. Кроме
того, он останавливает длительные запросы до того, как они начнут выполняться,
а не ждет, пока они проработают больше заранее заданного предельного времени.
Microsoft SQL Server Profiler — это
графическая утилита, позволяющая системным администраторам следить за событиями
в механизме базы данных. Примерами таких событий могут
служить:
· Подключение
к системе, неудачное подключение и отключение пользователя
· Операторы
SELECT, INSERT, UPDATE и DELETE языка Transact-SQL
· Состояние
пакетов вызовов удаленных процедур (RPC — remote procedure call)
· Начало
или конец выполнения хранимой процедуры
· Начало
или конец выполнения операторов в хранимой процедуре
· Начало
или конец выполнения пакета SQL - команд
· Получение
и освобождение блокировок (locks) на объекте базы
данных
· Открытие
курсора
· Отсутствие
статистики, вынуждающее оптимизатор запросов строить догадки о селективности
предикатов
Данные о каждом событии можно перехватить и сохранить в
файле или таблице SQL Server для последующего анализа,
а также отфильтровать, чтобы выделить представляющее интерес подмножество.
Например, мы можем сохранять лишь события, связанные с конкретной базой данных
или пользователем, и игнорировать все остальные. С
другой стороны, можно было бы собирать данные только о тех запросах, для
выполнения которых потребовалось более 30 секунд.
SQL Server Profiler позволяет
воспроизвести для SQL Server захваченные данные о
событиях, что фактически обеспечивает повторное
выполнение сохраненных событий в том порядке, как они происходили первоначально. Для устранения проблем в SQL Server
вы можете захватить всю приводящую к проблеме последовательность событий, а
затем повторить ее на тестовой системе, чтобы воспроизвести и устранить сбой.
Мастер настройки индекса (Index Tuning
Wizard) Microsoft SQL Server представляет собой
новый мощный инструмент, который анализирует рабочие нагрузки и рекомендует
оптимальную конфигурацию индексов для базы данных.
В частности, этот мастер обладает следующими возможностями:
· Осуществляет
сравнение, сопоставление и выбор наилучшей комбинации индексов на основе
расчета затрат, проводимого оптимизатором запросов.
· Рекомендует
лучший набор индексов для определенной рабочей нагрузки на базу данных,
заданной в виде файла трассировки или сценария SQL.
· Обеспечивает
анализ индексов, рабочих нагрузок, использования таблиц и затрат на запросы.
· Выполняет
настройку для полной рабочей нагрузки и при этом может отбрасывать существующие
индексы, чтобы снизить затраты на поддержку базы данных.
· Выполняет
настройку базы данных для группы проблемных запросов без отбрасывания существующих
индексов.
· Создает
прототип рекомендуемой конфигурации индексов для других ограничений по
дисковому пространству.
Мастер настройки индексов формирует операторы SQL, позволяющие отбросить неэффективные индексы или создать
новые, более эффективные индексы и статистику по неиндексированным столбцам. При необходимости эти операторы можно сохранить, чтобы
выполнить вручную.
При создании индекса Microsoft SQL Server автоматически
сохраняет статистическую информацию, касающуюся распределения значений в
индексируемых столбцах. SQL Server 7.0 поддерживает
также статистику для неиндексированных столбцов. Оптимизатор
запросов опирается на эту информацию при оценке объема промежуточных
результатов запроса, а также затрат на использование индексов для него.
Если оптимизатор определяет, что для оптимизации запроса не
хватает важного статистического параметра, он автоматически строит
соответствующую статистику. Такая автоматически
созданная статистическая информация сохраняется в базе данных и может
использоваться для оптимизации других запросов. Впрочем, через какое-то время
эта информация точно так же исчезает, если она не потребовалась снова. Более того, SQL Server автоматически
обновляет статистическую информацию, когда данные в таблице меняются и эта
статистика становится устаревшей.
Высокую эффективность построения и обновления статистики
обеспечивает выборка (sampling), выполняемая по
различным страницам данных. При этом из таблицы или
некластеризованного индекса извлекаются данные для наименьшего индекса,
содержащего необходимые для статистики столбцы. Частота
обновления статистической информации определяется объемом данных в таблице и
степенью их изменчивости. Например, статистика для
таблицы с 10000 строк может потребовать обновления при изменении 1000 строк,
поскольку это число составляет значительную часть таблицы. В
то же время для таблицы из 10 миллионов строк 1000 изменений будет менее
значима.
В этом документе описываются инновации и усовершенствования
в процессоре запросов Microsoft SQL Server 7.0. Оптимизатор
запросов SQL Server 7.0 применяет множество изощренных
приемов для определения оптимального плана выполнения и располагает многими
новыми возможностями, обеспечивающими быстрое и эффективное выполнение таких
планов. Хотя некоторые из этих средств работы с
запросами доступны также в других коммерческих серверах баз данных, ни один из
них не может предложить такой легкости использования и хорошей интеграции с
семейством операционных систем Microsoft Windows.
Чтобы получить дополнительную информацию о Microsoft
SQL Server, посетите веб-узел SQL Server по
адресу www.microsoft.com/sql/.
Чтобы получить дополнительную информацию о
Microsoft SQL Server 7.0, вы можете обратиться к следующим источникам:
· Microsoft
SQL Server 7.0 Books Online
· Microsoft
BackOffice® Resource Kit
· Различные
статьи Microsoft Knowledge Base, доступные на CD-ROM TechNet
Служба Microsoft Education Services и
авторизованные учебные центры предлагают курсы обучения использованию SQL Server. Для получения дополнительной информации свяжитесь
с Microsoft Customer Service по телефону (800) 426-9400.