
Implementing Large Decision Support
Databases
with Microsoft SQL Server 7.0
The information contained in this document represents the current view of Microsoft Corporation on the issues discussed as of the date of publication. Because Microsoft must respond to changing market conditions, it should not be interpreted to be a commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of any information presented after the date of publication.
This document is for informational purposes only. MICROSOFT MAKES NO WARRANTIES, EXPRESS OR IMPLIED, IN THIS DOCUMENT.
©1998 Microsoft Corporation. All rights reserved.
Microsoft, ActiveX, Visual FoxPro, and Windows NT are either registered trademarks or trademarks of Microsoft Corporation in the United States and/or other countries.
Other trademarks and tradenames mentioned herein are the property of their respective owners.
Microsoft Part Number: 098-81102
Contents
Introduction to Decision Support Systems and SQL Server.........................................................................
DSS vs. OLTP.....................................................................................................................................................
Hardware and Performance Metrics.............................................................................................................
Hewlett-Packard Server...........................................................................................................................
EMC Storage..............................................................................................................................................
EMC Symmetrix 3430-18.......................................................................................................................
Overview of DSS Issues...................................................................................................................................
Server Configuration in DSS................................................................................................................................
Automatic Resource Management................................................................................................................
SQL Server 6.5 Resource Allocation...........................................................................................................
Creating the DSS Database.................................................................................................................................
SQL Server 7.0 Filegroups and Files............................................................................................................
Filegroups and I/O Strategies........................................................................................................................
Read-only Filegroups.....................................................................................................................
Filegroups and Proportional Filling..............................................................................................................
SQL Server 7.0 Comparison to SQL Server 6.5.........................................................................................
SQL Server 7.0 Database Creation Metrics...............................................................................................
Loading the DSS Database..................................................................................................................................
The bcp Utility.................................................................................................................................................
BULK INSERT Statement............................................................................................................................
Data Transformation Services.....................................................................................................................
Distributed Queries..........................................................................................................................................
Striping..............................................................................................................................................................
Loading Considerations and I/O Strategies...............................................................................................
Design Considerations with SQL Server 7.0...............................................................................................
Disk Management in SQL Server 6.5..........................................................................................................
Disk Management in SQL Server 7.0..........................................................................................................
text and image Values...................................................................................................................................
SQL Server 7.0 Load Metrics........................................................................................................................
Indexing Strategies in the DSS Database.........................................................................................................
Microsoft SQL Server 7.0 Indexing Enhancements.........................................................
Index Architecture..........................................................................................................................................
Clustered Indexes...................................................................................................................
Nonclustered Indexes.............................................................................................................
Heap Tables.............................................................................................................................
Index and Performance Issues in SQL Server 6.5....................................................................................
Index and Performance Issues in SQL Server 7.0....................................................................................
Index Creation in SQL Server 7.0................................................................................................................
Parallel Index Creation in SQL Server 7.0..................................................................................................
Index Tuning Wizard.....................................................................................................................................
Accessing the DSS Data........................................................................................................................................
Query Optimizer..............................................................................................................................................
Limitations of the SQL Server 6.5 Query Optimizer.................................................................................
Goals of the SQL Server 7.0 Query Optimizer...........................................................................................
Parallel Queries................................................................................................................................................
Hashing.............................................................................................................................................................
Union Views for Partitioned Queries............................................................................................................
SQL Server 6.5 Statistics and Index Selection...........................................................................................
SQL Server 7.0 Optimization........................................................................................................................
Statistics on Nonindex Columns..........................................................................................................
SQL Server 7.0 Stored Procedures.......................................................................................................
SQL Server Profiler, Tracing, and Query Performance....................................................................
Normalization, Deferred Name Resolution, and Compilation.......................................................
Distributed Queries..................................................................................................................................
Heterogeneous Queries..........................................................................................................................
Managing DSS Databases....................................................................................................................................
Backup and Restore.......................................................................................................................................
Incremental Loading Techniques................................................................................................................
Integrity Issues................................................................................................................................................
Checking SQL Server 6.5 Databases...................................................................................................
Checking SQL Server 7.0 Databases...................................................................................................
Conclusion...............................................................................................................................................................
Microsoft® SQL Server™ is one of the leading database solutions on the Windows NT® operating system and breaks new ground in the enterprise space with the release of version 7.0. Redesigned for the enterprise, SQL Server 7.0 sets the quality standard by which all will be measured in terms of scalability, high performance, and ease of use.
This document reviews the decision support systems (DSS) features of Microsoft SQL Server version 7.0. In addition to information about the enterprise features of SQL Server 7.0, this document contains practical examples, performance metrics, and comparisons to SQL Server version 6.5.
DSS vs. OLTP
DSS and online transaction processing (OLTP) have different objectives, performance profiles, and resource requirements. SQL Server 6.5 is designed primarily for OLTP. SQL Server 7.0 is well equipped to meet the demanding requirements of both large DSS workloads and OLTP.
DSS users often access large volumes of data. Index access is frequently not available. Consequently, DSS workloads require large sequential I/O and block transfers. Typical DSS functions include report generation, aggregations, and analysis activities that require scans of large portions of data. Such I/O-oriented activity benefits from physically contiguous data access to minimize disk arm movement. DSS objectives are measured in megabytes (MB) per second. Techniques geared toward the DSS community include large I/O strategies and parallel operations and scans.
The revamped storage engine and new optimization techniques of SQL Server 7.0 meet the rigorous resource requirements of DSS. Industry-leading ease-of-use features range from dynamic resource management to autoshrink file storage. SQL Server 7.0 is unparalleled in maximizing the efficiency of administrative resources.
OLTP activities typically involve short transactions and small units of I/O. Rather than the long transactions and large I/O requirements of DSS, OLTP users usually require small amounts of random page I/O. More disk arms benefit such activity. Consequently, OLTP objectives are measured in I/O (page) and transactions per second or per minute.
Hardware and Performance Metrics
The performance metrics presented in this document were obtained using Hewlett Packard and EMC hardware. The test results prove that large-scale (500 GB or more) databases now can be created, loaded, indexed, and deployed in a few days with industry-standard technology and at a low cost.
The metrics are based on a 500-GB database, comprised of 380-GB data plus indexes and 120 GB of free space. In addition, tempdb (temporary space) was sized at 100 GB. The 380 GB data and index was loaded from 120 GB of raw data. Of the 380 GB of data and index, approximately 140 GB is data and 240 GB is indexes. The solution from Hewlett-Packard and EMC proves for the first time that the symmetric multiprocessing capabilities of four-way processing can optimize database queries effectively.
Hewlett-Packard Server
The Hewlett-Packard hardware had these specifications:
· Hewlett-Packard NetServer LXr (4x200 MHz PentiumPro, Rackmounted)
· 4-GB memory
· 8 x Adaptec 3944AUWD two-port differential SCSI adapter cards
· 2 x 10 KB RPM disk drives
· One 10/100TX Network Interface Card
· One 17-inch monitor
· Two DLT4215 15-slot storage libraries
EMC Storage
The EMC Symmetrix Enterprise Storage Systems are high-availability, disaster-tolerant subsystems capable of existing in a heterogeneous environment. The Symmetrix is based upon an Intelligent Storage Architecture that allows customers to consolidate core management functions: backup/restore, hierarchical storage management, disaster recovery, migration and sharing into one consistent point from which to manage, protect, and share information.
During the initial stages of the project, two EMC model 3400s provided 700+ GB of usable RAID-1 protected storage. The two systems were configured in the following manner:
· 4-GB dedicated, nonvolatile, intelligent cache
· 32 – 23-GB 5.25-inch drives
· Four Fast Wide Differential (FWD) SCSI Director/Adapter pairs, each with four SCSI ports, totaling 16 FWD SCSI channels
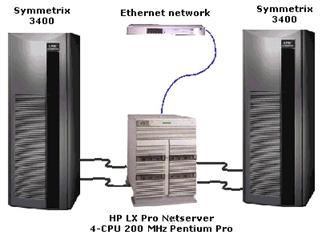
Each Symmetrix system was connected to the HP LX Pro NetServer by two FWD SCSI channels for a total of 40 MB/s bandwidth. The Symmetrix can carve its internal drives into partitions called hypervolumes. In this scenario the disk was divided into 3:1 splits of 9 GB, 9 GB and 4 GB respectively. Windows NT Disk Administrator was used to create striped volume sets with the 9-GB hypervolumes, minimizing the chances of disk spindle contention.
The intelligent, high-speed cache inherent in all Symmetrix systems also provided several benefits. A prefetching algorithm dynamically detects sequential data access patterns on the disk devices and pre-stages the blocks of data most likely to be used into the Symmetrix cache. Also, operations within the Symmetrix are split into two functional parts: the channel director and the disk director. Splitting the functions eliminates the processing overhead and cache locking associated with control units that perform both functions. Each disk device within the Symmetrix also has its own microprocessor and buffer, which add another level of caching and improve overall performance.
Both Symmetrix configurations worked well for the initial, smaller databases created during the course of the project. However, as the database size increased, it became evident that enhanced storage with more channel bandwidth would be beneficial. At this point, the two EMC 3400s were replaced with one EMC Symmetrix 3430-18.

EMC Symmetrix 3430-18
The Symmetrix 3430-18 had these specifications:
· 4-GB dedicated, nonvolatile, intelligent cache
· 96 18.1-GB 3.5-inch drives
· Four Ultra SCSI Director/Adapter pairs, each with four SCSI ports, totaling 16 Ultra SCSI channels
With more than 850 GB of usable, RAID-1 protected storage, the newer Symmetrix had more storage capacity than the previous two systems combined. The new 18-GB disk drives had internal disk transfer rates that were 40 percent faster on average than the earlier 23-GB drives. The new Symmetrix was connected to the HP LX Pro Server through eight Ultra SCSI ports. The increased number of ports and the switch from FWD to Ultra SCSI quadrupled the available channel bandwidth.
The new system was configured with 96 9-GB RAID-1 hypervolumes (2:1 splits). Twelve of these hypervolumes were assigned to each Ultra SCSI channel on which the Windows NT Disk Administrator was used to create a 108-GB stripe set. By spreading out the larger/busier tables of the database across these eight volume groups, higher I/O bandwidth was provided where it was needed.
Overview of DSS Issues
This document presents the entire cycle of a Microsoft SQL Server 7.0 decision support system, which includes initially setting up the database, loading data, indexing, accessing data, performing on-going incremental loading, and resolving management issues. Where appropriate, architectural enhancements and resulting DSS performance implications are highlighted. The time-consuming components of DSS database creation are creating and loading the database, and indexing the data. In addition, on-going issues pertaining to data access and maintenance the data must be considered.
Microsoft SQL Server 7.0 leads the industry in automatic resource management. Effective and efficient, automatic resource management sets a new standard for ease-of-use by reducing administration.
SQL Server memory, for example, is automatically managed through a collaboration of Microsoft Windows NT and SQL Server 7.0. As user workloads dictate, SQL Server 7.0 memory grows and shrinks automatically. When the workload increases, SQL Server 7.0 requests additional resources from Windows NT to keep pace with its memory needs. This is ideal for the varying, resource-intensive requirements of DSS.
Automatic Resource Management
By default, SQL Server can dynamically change its memory requirements depending on available system resources. SQL Server adds memory to the buffer cache when its workload requires more memory and releases memory resources when its workload is reduced.
When SQL Server is using memory dynamically, it queries the system periodically to determine the amount of free physical memory available. SQL Server grows or shrinks the buffer cache (data and index pages in memory) to keep sufficient physical memory available and prevent Windows NT from paging. When conditions warrant, SQL Server releases memory to Windows NT for use by other processes. When more physical memory than Windows NT needs to prevent paging is available, SQL Server recommits memory to the buffer cache. A server at rest does not grow its buffer cache.
It is recommended that SQL Server be configured to use memory dynamically. However, you can manually set the memory options and override SQL Server’s ability to use memory dynamically. Before you actually set the amount of memory to be used by SQL Server, determine the appropriate memory setting by subtracting the memory required for Windows NT (and other system uses, if the computer is not wholly dedicated to SQL Server) from the total physical memory. This is the maximum amount of memory you should assign to SQL Server.
If you want to allow other applications to use memory resources, set minimum and maximum limits for memory allocation using the advanced SQL Server configuration options: max server memory (MB) and min server memory (MB). Within these boundaries, SQL Server 7.0 can request additional memory and release excess memory.
SQL Server 6.5 Resource Allocation
In SQL Server version 6.5, resource allocation is static. The memory configuration option fixes the size of memory allocated to SQL Server 6.5. Given this fixed memory, other configuration options such as procedure cache, locks, user connections, sort pages, max worker threads, hash buckets, set working set size, max async IO, and free buffers determine how the memory is partitioned or allocated.
There are three distinct disadvantages with SQL Server 6.5 static resource allocation. Any configuration option that affects memory, and hence static resource allocation, requires:
· Continual administrative review to ensure peak performance.
· Overcommitment of resources to handle peak periods.
· A restart of SQL Server for any changes to take effect.
The first step, and probably the single most significant task performed by a database administrator, is database creation, which means specifying to SQL Server 7.0 where data will be stored on disk. Optimal database behavior includes minimal disk arm movement, minimal conflict for individual disk drives and I/O channels, and overall highest I/O rates.
Because this process is I/O-intensive, the fastest way to create a database is to saturate I/O resources. Fortunately, the strategy of saturating I/O resources to create a database efficiently is also quite effective for good DSS query performance.
Decision support environments are particularly sensitive to I/O constraints. Unlike their relatively simple transaction processing counterparts, decision support queries tend to access large volumes of data. Speed means, literally, the ability to pull the maximum amount of data from disk in the minimal amount of time.
Because DSS tends toward large transactions involving large chunks of data, peak performance of the I/O subsystem is essential. SQL Server 7.0 provides new I/O strategies that are ideally suited for DSS. The capacity of the CPU is the fixed limitation of the system. In a perfect I/O environment, the I/O subsystem provides enough throughput to allow for CPU saturation.
SQL Server 7.0 Filegroups and Files
SQL Server 7.0 introduces the filegroup and file concept, which replaces the static database devices and database segments concepts of SQL Server 6.5. A SQL Server 7.0 database can reside on one or more filegroups. The number of filegroups to consider depends on factors such as recovery considerations, I/O requirements (for example, the need for multiple spindles, arms, or minimal contention), and segregation of data.
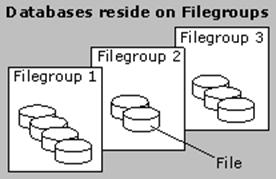
A filegroup is a collection of data files. Files in a filegroup can be located on different disks. Multiple files in a filegroup permit parallel I/O scan operations.
Each file has one or more index allocation maps (IAM) for objects. IAM pages map the extents in a database file used by an object (heap table or index). Each heap or index has one or more IAM pages that record all the extents allocated to the object.
The IAM allows SQL Server 7.0 to perform fast physical order scans. In the case of scans, I/O requests are issued in parallel for each file in disk order. Parallel scans are an important consideration for DSS performance strategies.
When a table or index is created, it is assigned to a filegroup. Tables, indexes, text, ntext, and image data can be associated with a specific filegroup. Space for a table or index is allocated from the files within the filegroup. A file cannot be a member of more than one filegroup.
From a maintenance standpoint, the smallest unit of recovery is a file. It may be desirable to create a filegroup containing a single file. If a single table is assigned to a filegroup, table-level recovery is possible.
SQL Server 7.0 files can dynamically grow to keep pace with the increasing database size. In contrast to SQL Server 6.5 fixed database device sizes (which require monitoring free space), dynamic growth minimizes administration. It is possible to create a fixed file size or to allow for specific increments of growth in MB or percentages.
Dynamic growth does present a performance issue to consider, especially in tempdb. Automatic growth carries a performance penalty because all operations stop until the growth is complete. The following scenario explains why dynamic growth can have a 5-to-10-percent performance impact in tempdb (or log) if I/O is a resource bottleneck and the dynamic growth parameters are set too low.
tempdb is commonly used for joins, sorts (ORDER BY, GROUP BY, DISTINCT, and so on) and normal temporary table allocation. Such activity is common in DSS; therefore, tempdb dynamic growth can become a bottleneck if its use is high and the initial size and growth increment is correspondingly small. In such cases continuous dynamic growth (and shrinking) can occur. Another factor to consider is that dynamic growth competes with other I/O activity on a particularly busy drive when the new portion of the file is initialized.
It is preferable to preallocate tempdb to avoid dynamic growth in high usage scenarios. Because tempdb shrinks back to its original size when SQL Server 7.0 is restarted, examine the size of tempdb during peak activity and preallocate tempdb by altering it to this size. As an additional consideration, the growth increment should be sufficiently large, depending on the usage of tempdb, to avoid excessive dynamic growth if activity goes beyond the preallocated size.
If the transaction log for a database is very small, and its growth increment is also small, a busy system with high logging activity could be similarly constrained by dynamic growth. For OLTP, the transaction log grows based on activity. For DSS, the transaction log typically grows during periodic loading cycles.
The theoretical limit for a single database is 32,767 files. Each file can contain 32 terabytes (TB) per file for a maximum of a 1,000,000-TB database.
Filegroups and I/O Strategies
Filegroups provide a way to segregate I/O traffic by individual tables and indexes in a database. Effectively using filegroups for this purpose requires knowing how much I/O activity is generated by individual tables and indexes. In contrast, using a single database file on a striped disk array provides good load balancing but does not take advantage of any application-specific knowledge about I/O access patterns. Use segregation to avoid I/O contention.
You can use filegroups to segregate your data and control I/O. By creating multiple filegroups and assigning objects to them, you can create an I/O strategy that isolates a hot table in its own filegroup. For example, an important large table may be placed alone on a filegroup to ensure that there will be no I/O contention with other objects.
Consider a case in which two tables are being loaded simultaneously. Extents are allocated serially, so the two tables will have interleaved extents. A scan of one table would have to bypass the interleaved extents of the other table, resulting in lower disk throughput. Creating multiple indexes simultaneously results in exactly this behavior.
Another way to use filegroups is to separate tables which are mainly accessed randomly (typical of OLTP) from tables which are accessed sequentially (typical of DSS). Random access I/Os are usually small and require disk arm movement. Sequential access I/Os are usually large and require few disk seeks. By separating them, the performance of both improves.
Read-only Filegroups
SQL Server 7.0 allows filegroups to be marked as read-only. A filegroup marked read-only cannot be modified in any way. Any existing filegroup, including the primary filegroup, can be marked read-only. If the primary filegroup is marked read-only, no new objects can be created in the database. For example, the creation of any new object, such as a table, view, database user, stored procedure, or automatic stored procedure recompilation, updates the system tables. This would not be possible if the primary filegroup were marked read-only.
Place tables that must not be modified, such as historical data, on filegroups and then mark those filegroups read-only to prevent accidental updates. The read-only filegroups can then be backed up and restored on another server running SQL Server without concern for recovery of transaction logs.
Filegroups and Proportional Filling
SQL Server 7.0 implements a feature called round robin allocation, in which data is distributed across a set of data files. If a database resides on four data files, one-fourth of the database resides on each file. Furthermore, extents are placed on alternating data files so that sequentially-assigned extents reside on alternating data files.
Proportional filling means that as objects assigned to the filegroup grow in size, pages are allocated in equal proportion on each file in the filegroup. This organization is ideal for both data file creation and subsequent usage.
SQL Server 7.0 initializes all data files in parallel, where possible. For example, if you specify that a database is to be created on four data files, SQL Server 7.0 initializes all four data files in parallel.
Data file initialization is done in parallel when multiple file specifications occur within one CREATE DATABASE or ALTER DATABASE statement. Furthermore, the degree of parallelism is dependent upon the number of Windows NT drives in the specification. For instance, if a CREATE statement contains three data files, one of which is on drive D and two of which are on E, then the D: file will be initialized in parallel with the data files that are on drive E, producing two-way parallelism.
Just like the parallel data file initialization for the database, the data files of each filegroup are initialized in parallel. Assuming that each data file resides on a different I/O interface, the initialization time is the write throughput of the I/O interface. Likewise, the SQL Server 7.0 parallel scan throughput is the read throughput of the I/O interface (up to the limits of processor capacity).
This implementation specifies a filegroup per table and a filegroup per index. The SQL Server 7.0 query processor scans indexes just as it would scan tables, if a query can be satisfied from the index by itself. It is important to have contiguous index space just as you have contiguous table space.
Each filegroup defines a separate access domain. For optimal performance of large objects, there should be one filegroup for each (large) table and index. The following is an example of a CREATE DATABASE statement for filegroup. There are two filegroups in this example: primary and DSS_FG2. Note the initial size, maximum size, and file growth values.
CREATE DATABASE dss_db
ON PRIMARY
( NAME = dss_PrimaryFG_file1,
FILENAME = 'd:\dss\dss_PrimaryFG_file1.mdf',
SIZE = 50 MB,
MAXSIZE = 500 MB,
FILEGROWTH = 15% ),
( NAME = dss_PrimaryFG_file2,
FILENAME = 'e:\dss\dss_PrimaryFG_file2.mdf',
SIZE = 50 MB,
MAXSIZE = 500 MB,
FILEGROWTH = 15% ),
FILEGROUP DSS_FG2
( NAME = dss_FG2file1,
FILENAME = 'f:\dss\dss_file1.mdf',
SIZE = 50 MB,
MAXSIZE = 500 MB,
FILEGROWTH = 5 MB ),
( NAME = dss_FG2file2,
FILENAME = 'g:\dss\dss_file2.mdf',
SIZE = 50 MB,
MAXSIZE = 500 MB,
FILEGROWTH = 5 MB)
LOG ON
( NAME = 'dss_log',
FILENAME = 'h:\dss\dss_log.ldf',
SIZE = 10 MB,
MAXSIZE = 50 MB,
FILEGROWTH = 5 MB )
This is an example of an ALTER DATABASE statement to add a filegroup and two files:
ALTER DATABASE dss_db ADD FILEGROUP DSS_FG3
ALTER DATABASE dss_db ADD FILE
(NAME= dss_FG3file1,
FILENAME= 'k:\dss\dss_file1.ndf',
SIZE=50 MB),
(NAME= dss_FG3file2,
FILENAME='m:\dss\dss_file2.ndf',
SIZE=50 MB)
TO FILEGROUP DSS_FG3
You can estimate the size requirement of each data file by adding 10 percent to the size of the input file or, in the case of an index, the width of the index columns. The actual size will vary with the data types defined in the table and data file.
SQL Server 7.0 Comparison to SQL Server 6.5
In SQL Server version 7.0, it is possible to create databases at the I/O throughput rate of the system. Database creation is a pure write operation, so the maximum rate is not the general I/O rate of the system. Instead, it is the output rate of the system, which is usually slower than the input rate.
Unlike the relatively slow CREATE DATABASE process of SQL Server version 6.5, which does not use parallel I/O for initialization, SQL Server 7.0 CREATE DATABASE operates in parallel (across multiple disks simultaneously) at near device speed. This occurs because of a new technique in SQL Server 7.0 called scatter/gather I/O. During database creation, scatter/gather I/O allows SQL Server 7.0 to project or replicate a single initialized page for all pages in the database. These pages are then written to disk using large I/Os (1 MB) at near device speed.
Rather than replicating one initialized page, SQL Server 6.5 creates four extents in cache (64-KB blocks or 32 zero-initialized pages) and writes them to disk. For every 1-MB write in SQL Server 7.0, SQL Server 6.5 does 16 writes.
Object placement in SQL Server 6.5 is accomplished with segments that map to database devices. If a segment spans multiple database devices, extents can be obtained from any of these devices.
SQL Server 6.5 segments provide a very crude and imprecise method balance loads because extents are allocated sequentially on a device. Because it is not possible to control where an extent is allocated when a segment spans multiple devices, load balancing is nearly impossible. In contrast, the round-robin, proportional filling of SQL Server 7.0 guarantees load balancing by ensuring that each file in the filegroup is used or filled equally.
A comparison of SQL Server 6.5 and SQL Server 7.0 table scan performance can help determine how to set up filegroups and files for loading and accessing data.
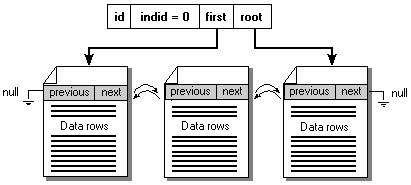
In SQL Server 6.5 all pages in a table are linked together with next and previous pointers. When doing a table scan, SQL Server 6.5 performs link list-oriented I/O. That is, the link list is followed sequentially to read in all pages. Consequently, reading link lists that are noncontiguous requires read/write head movement and is much slower.
This illustration link shows list order scans in SQL Server 6.5.
In contrast to SQL Server 6.5 link list order table scans, SQL Server 7.0 performs parallel disk order scans to read in all pages of an object. By using the index allocation map for each file, SQL Server 7.0 identifies all pages owned by an object without following the link list.
This illustration shows disk order scans in SQL Server 7.0.
SQL Server 7.0 Database Creation Metrics
On the EMC test system, a sustained database creation rate of 63 MB/second was achieved, approximately the limit of the particular 8 Ultra FW/SCSI-II configuration. The creation of a 400-GB database required in 2 hours 53 minutes for an aggregate rate of over 147 GB/hour.
On a six ultrawide-SCSI-channel configuration using directly connected 10-KB drives (10 KB RPM), sustained database creation rates of 110 MB per second were achieved, equating to 387 GB per hour. Given the 1-MB writes of SQL Server 7.0, this is 110 writes per second. Thus, database creation operates at channel speed.
At very high speeds, PCI buses eventually saturate. In such cases, adding further interface cards will not increase throughput. When quantifying PCI bus limits, the determining factor is the bus efficiency of the interface cards. The capability of the Symmetrix to be configured for various types of operations meant that the test system was not optimized for a create index operation.
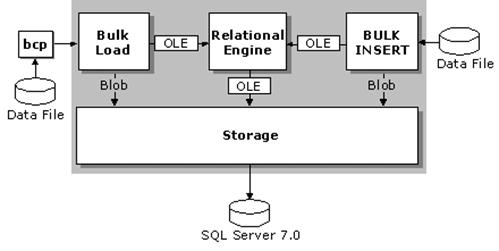
An important consideration for DSS environments is the speed at which data can be loaded and made available for use. Microsoft SQL Server 7.0 provides a number of data loading alternatives, including bulk copy program (bcp utility), BULK INSERT (Transact-SQL), Data Transformation Services (DTS), and distributed queries. In addition, database backups from one SQL Server can be loaded into another.
Historically, the bcp utility has been used for fast loading of SQL Server databases. Although bcp has been improved significantly in SQL Server 7.0 (now using ODBC API instead of DB-Library), it still runs out of process, incurring the expense of context switching when it hands data over to SQL Server. The handling of complex data types and translation from external to internal formats is greatly improved.
BULK INSERT offers superior load performance, and DTS provides data transformation functionality for imports from or exports to heterogeneous data sources. If transformations are not required, distributed queries can be used to export data from heterogeneous data sources.
The bcp Utility
With SQL Server 7.0, bulk copies to tables with indexes are more efficient than they were with SQL Server 6.5. Type checking and index processing are faster. Secondary index values are spooled, rather than applied immediately.
SQL Server 6.5 does index sorting while the bulk copy data is loading. In contrast, SQL Server 7.0 uses the spool to order nonclustered indexes after the table is loaded. The benefit of SQL Server 7.0 index processing requires less work; the index entries are handled once by the spool. In addition, minimal logging is performed for undo operations.
SQL Server 7.0 permits parallel bulk copy loads to a single table. This requires indexes to be dropped before running parallel loads to a single table.
During a bulk copy load, bcp reads a file and passes the data to SQL Server for loading. The bcp utility operates as a separate process from SQL Server. An application that runs outside of another process, in this case SQL Server, is commonly described as being out of process. Out-of-process operations require context switching to pass data. Consequently, out-of-process operations are not as efficient as in-process operations.
BULK INSERT Statement
BULK INSERT is a new SQL Server 7.0 Transact-SQL statement that is issued either programmatically or through the osql. With BULK INSERT, the SQL Server 7.0 engine reads and formats the input data files in-process, a very efficient operation.
Using BULK INSERT results in a performance 2.5 times improved over bcp because the requirement of passing data from one process to another is eliminated. In other words, the in-process nature of BULK INSERT avoids expensive context switching.
Bulk insert uses the OLE DB API to read the underlying file as a heterogeneous data source. Multiple bulk insert statements can execute concurrently, providing the ability to take advantage of all processors in a symmetric multiprocessing configuration. Like parallel bulk copy, there can be no indexes if a parallel bulk insert is performed on a single table.
The illustration shows bcp (out-of-process) and bulk insert (in-process).
 This is an example of a bulk insert statement:
This is an example of a bulk insert statement:
Bulk insert lineitem from ‘e:\lineitem.tbl.1’
The next step to implement high speed loading is to execute multiple bulk insert threads in parallel. Several actions must be taken to allow parallel execution.
First, the switch TABLOCK must be added as a parameter to the bulk insert statement. A table can be loaded by multiple clients concurrently (in parallel) only if the table has no indexes and TABLOCK is specified. By default, locking behavior is determined by the table option table lock on bulk load. This instructs bulk insert to lock at the extent rather than the table level.
Second, a parallel load to a single table does not permit indexes on the table during load. If there are no indexes, bulk copy is minimally logged. Minimally logged means that data is not logged but logging is performed to enable undoing the allocations if the load fails in the middle and must be rolled back. In such cases, the database option select into/bulkcopy must be set on to allow a minimally logged bulk copy.
Last, your input file must be segmented into multiple files so that each bulk insert thread has a distinct input file. Execute multiple bulk insert statements. One way to do this is to use the START command from a command shell. Ideally, you would start one bulk insert per physical processor. For example, in a four-processor system, you would execute four parallel bulk insert statements, and in an eight-processor system you would execute eight parallel bulk insert statements.
This code sample shows parallel loading using multiple files:
FOR %i IN (1 2 3 4) DO
START isql –Usa –P –Q "bulk insert lineitem from lineitem.tbl.%I with (tablock)"
This code sample shows parallel loading using a single file:
START isql –Usa –P –Q"bulk insert lineitem_table from c:\data\lineitem.tbl"
-FIRSTROW 1 –LASTROW 500000
START isql –Usa –P –Q"bulk insert lineitem_table from c:\data\lineitem.tbl"
-FIRSTROW 500001 –LASTROW 1000000
The parallel bulk copy load samples use multiple SQL Server (for example, system process IDs, SPIDs, or threads). These SPIDs run in the context of the SQL Server process. By eliminating context switching and interprocess communication, bulk insert is almost 2.5 times more efficient than bcp.
After you start loading in parallel, any sorting of the input file will be lost. Consequently, subsequent creation of clustered indexes may take longer.
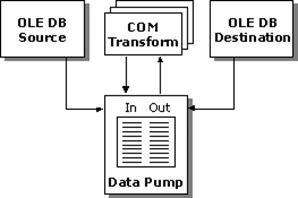
Data Transformation Services
Data Transformation Services (DTS) is a new component of SQL Server 7.0. It provides the functionality to import, export, and transform data between SQL Server and any OLE DB, ODBC, or text file format. For loading purposes, DTS enables SQL Server 7.0 to import data from or export data to any OLE DB or ODBC data sources.
DTS Data Pump, a multithreaded OLE DB service provider, is designed for high performance. It is extensible using COM and Microsoft ActiveX® scripts.
This illustration shows DTS functionality.
Importing and exporting data is the process of exchanging data between applications by reading and writing data in a common format. For example, DTS can import data from an ASCII text file or a Microsoft Access database into SQL Server. Alternatively, data can be exported from SQL Server to an OLE DB data destination, such as a Microsoft Excel spreadsheet.
A transformation is the sequence of operations applied to each row in a source rowset prior to sending it to the destination. For example, DTS enables the calculation of new values from one or more source fields, or even the breaking of a single field into multiple values to be stored in separate destination columns.
DTS is therefore an important tool for transforming and loading DSS data. Transformations make it easy to implement complex data validation, scrub data, and enhance data for import and export.
This illustration shows the DTS user interface for selecting an OLE DB or ODBC data source.
DTS can be used to filter the data to be transferred by column or by queries such as aggregations. This capability permits a DSS database to be built from OLTP databases without changing the underlying OLTP database structure.
This illustration shows the DTS user interface for column level filtering.
The following illustration shows a type of data transformation using query results. Select operations such as joins, aggregations, unions, distinct, and so on can be used to populate DSS destination tables. In such cases, you can specify an appropriate name for the result table.
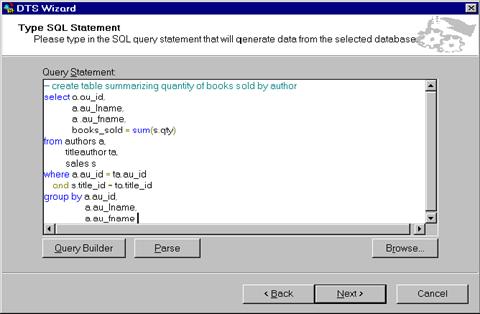
Distributed Queries
If no data transformation is required, DSS databases can be populated by using distributed queries. Distributed queries access data stored in multiple data sources on either the same or different computers. These queries take advantage of OLE DB, the emerging standard for data access of nonrelational as well as relational data sources.
Distributed queries provide SQL Server users with access to data stored in:
· Multiple servers running SQL Server.
· Heterogeneous databases.
· File systems.
· Network sources.
Striping
Load balancing is desirable for optimum I/O performance. One way to achieve load balancing is by using striping. Multiple physical disks (spindles) can be connected together logically (associated) to form a logical drive. A technique called striping writes data to the logical disk by dividing the writes evenly across multiple physical disks. By using striping, reads and writes take place across more physical disks, providing more arms, load balancing, and quicker access to data.
Striping can be done at either the hardware level or by the Windows NT operating system. The number of drives that can be hardware striped together is limited, causing a software stripe scenario. On the other hand, there are limits on software striping too; specifically, 32 drives per NTFS stripe set. The decision to use hardware or software striping should be based on a consideration of the configuration and management trade-offs and an analysis of the performance characteristics of the specific hardware being used.
The simplest method of load balancing is to stripe across all disks. While striping across all disks provides load balancing, it does not necessarily solve contention problems between objects in the database, nor does it provide object placement capabilities.
By using filegroups and files, SQL Server 7.0 can further improve I/O subsystem performance. Thus, I/O strategies that consider contention issues and object placement can be implemented using SQL Server 7.0.
Loading Considerations and I/O Strategies
SQL Server 7.0 allows control over object placement and provides load balancing with filegroups and files. The two strategies to consider are a uniform distribution strategy (for example, striping) or segmentation (for example, filegroups and files).
The uniform distribution strategy, sometimes known as the wide stripe method, attempts to spread all data evenly across the maximum number of physical disk drives. When a filegroup is allocated to a contiguous area on each disk drive, an attempt to access that filegroup results in the minimal number of head positioning times. When a filegroup is distributed across a large number of physical disk drives, the likelihood of head contention decreases.
The segmentation strategy isolates tables to specific sets of disk drives. In data warehouse-style queries, it is common to join a large fact table to smaller dimension tables. Often the fact table is placed on one large set of disk drives and the dimension tables on another, smaller set of disk drives. In this case, the random access head positioning for the dimension tables does not affect the sequential access to the fact tables.
This illustration shows both striping and segmentation using RAID.
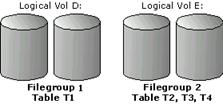
Filegroup 1 consists of a single file on logical volume D. Logical volume D is a RAID stripe set consisting of multiple physical disks. Filegroup 2 consists of a single file on logical volume E. Logical volume E also is a RAID stripe set consisting of multiple physical disks.
If you are not using RAID, you may still achieve load balancing by setting up a filegroup that spans a number of disks that use multiple files. For example, Filegroup 1 includes file 1 on drive E and file 2 on drive F, and Filegroup 2 includes files on drives G through J.
At the filegroup level, SQL Server provides a round-robin method of balancing the loading of the files in a filegroup. It does so by proportionally filling each file in the filegroup.
This illustration shows striping and segmentation without RAID.

For DSS operations (large I/O requests), the highest I/O rates can be achieved with contiguous, sequential extent allocation.
Design Considerations with SQL Server 7.0
SQL Server 7.0 has a page size of 8 KB. SQL Server 6.5 has a page size of 2 KB. The larger page size in SQL Server 7.0 means that the row size restriction of 1,962 bytes for SQL Server 6.5 is increased to 8,060 bytes in SQL Server 7.0. The possibility of wider rows facilitates the tendency in DSS databases toward denormalized tables. Denormalized tables avoid joins by providing more columns, and hence have wider rows than their normalized counterparts.
Furthermore, porting database designs from mainframes is easier because many are designed for the 4-KB pages of DB2. The 8-KB page is even more efficient than the 4-KB page. For example, if your design had a row size of 1,050 bytes, three rows would fit on a DB2 4-KB page and seven on a SQL Server 7.0 8-KB page. On a SQL Server 6.5 2-KB page, only one row will fit. On a percentage basis, there is more wasted space on a smaller page. Consequently, the 8-KB page is more efficient for any large I/O operation, such as the table scans common in DSS.
A subtler factor is the number of index levels. With SQL Server 6.5, more index levels must be maintained because there are at least four times as many leaf pages in a large table. The 8-KB intermediate index pages of SQL Server 7.0 can store four times as many entries as their SQL Server 6.5 counterparts; the number of index levels will be substantially less in SQL Server 7.0.
Disk Management in SQL Server 6.5
SQL Server 6.5 uses a fixed-size database device model. Databases are placed on the database devices. Continuous management is required to monitor remaining space.
SQL Server 6.5 provides very limited I/O balancing and object placement using segments that map to database devices. Tables and indexes can be placed on segments; indirectly, segments are used to place objects on devices.
Theoretically, if a segment spans multiple database devices, extents will be requested from any of the devices that map to the segment. However, in practice, the SQL Server 6.5 method of extent allocation is serial (sequential) allocation of extents (based on device order) within a segment. Thus, if Segment1 maps to multiple devices: DriveC_device, DriveD_device, and DriveE_device, extent allocation occurs sequentially on DriveC_device until all extents on DriveC_device are allocated. Then, extents on DriveD_device are allocated. Last, extents on DriveE_device are allocated. At best, SQL Server 6.5 provides very limited load balancing capabilities. In SQL Server 6.5, striping is the best way to achieve load balancing.
Disk Management in SQL Server 7.0
SQL Server 7.0 databases are created on filegroups. Filegroups consist of one or more files. Files and filegroups provide automatic growth and shrinkage, simplifying database management. In contrast, database devices in SQL Server 6.5 are static.
Automatic growth relieves the close management that was required of SQL Server 6.5 fixed database devices. Growth increments can be specified in percentage or absolute MB. A size limit can be set as an upper limit for growth, if you want.
SQL Server 7.0 objects such as tables or indexes can be assigned to a filegroup. The advantage to object placement is that important tables can be segregated to prevent I/O contention with other objects.
A filegroup containing a single file provides good physical access, if for example, a single table were placed on the filegroup. No other objects would contend for I/O in this case, assuming there are no other files on the disk. However, the load balancing features of SQL Server 7.0 only apply when a filegroup contains multiple files.
SQL Server 7.0 load balancing across files in a filegroup is achieved using round-robin allocation with proportional filling. Round-robin refers to a technique of sequentially assigning (allocating) extents in alternating data files in a filegroup. Proportional filling ensures that each data file is filled evenly with data. SQL Server 7.0 load balancing is ideal for the parallel reads and writes of DSS, in which large I/O operations are the norm.
For DSS operations generating large I/O requests, the highest I/O rates can be achieved with contiguous, sequential extent allocation across alternating data files. Contiguous extents minimize the disk head positioning time that is required when extents are intermingled with other objects’ extents.
For speed of load, SQL Server 7.0 provides superb parallel loading capabilities; however, if the objects are going to reside on the same filegroup, intermingling of extents occurs if the loads occur simultaneously. Parallel loads to different filegroups solves this problem. Parallel loads speed up the loading process while the different target filegroups prevent intermingled extents.
text and image Values
The SQL Server storage architecture has been changed in version 7.0 to provide efficient storage of large text and image values. It allows a B-tree structure over fragments and produces efficient read-ahead performance. Seeking to offsets is very efficient.
Small text objects share space on pages, resulting in much better space utilization. One of Microsoft’s internal OLTP databases that contains many small text values shrank from 110 GB on SQL Server 6.5 to only 85 GB on SQL Server 7.0.
SQL Server 7.0 Load Metrics
The in-process nature of bulk insert provides superior load performance. In measurements, load rates of 5.7 MB per second were consistently achieved on a NetServer LXr with four 200MHz P6 processors, each with 512 KB of L2 cache. For text and image data, bulk insert can sustain 12 MB per second with the same configuration. Using bcp, a sustained rate of 2.2 MB per second was achieved. (Single client loads using bcp in SQL Server 7.0 are approximately two times faster than SQL Server 6.5.) Bulk insert is the highest performance option for loading data.
During loads with bulk insert, all four processors are saturated. The I/O rate is slightly more than double the loading rate, which for this configuration is very far short of the disk and channel limitations. (The I/O rate is double the load rate because half of the I/Os are from reading the input files.) By using bulk insert, parallel loads into a single table scale linearly with the number of CPUs.
The requirements for loading a single table in parallel are no indexes on the table, and the number of insert streams must not exceed the number of available CPUs. After the load, the indexes can be created in parallel.
Creating indexes quickly and efficiently is important for any sizable database, such as a large DSS. Indexes provide alternative methods of accessing data other than the table scan. A table scan reads every data page for the table and is very expensive from an I/O perspective. If an index can be used to pinpoint the required rows without doing a table scan, it can be quite beneficial.
The traditional use of an index is to provide keyed or sorted access to a subset of data within a table. Another use of indexes, which is popular in DSS applications, is to provide a vertical subset of data within the table. For example, if a table contains 75 columns, but most queries examine only 10 columns, making an index containing only the 10 columns can reduce the amount of data required in a scan. This approach does lead to the creation of many indexes and occupies more storage, but the tradeoff can be significantly better query execution speed.
In an OLTP environment, the maintenance aspect of indexes is very important as inserts, deletes, and some updates require maintenance of nonclustered indexes. Index maintenance is also required for DSS, but is mainly confined to the batch update process. The tendency in DSS is to have more indexes because most user activity is read-oriented. Because most DSS activity is retrieval (reads), which has no index maintenance ramifications, the more helpful the indexes, the better. Of course, the indexes will be maintained during batch updates or incremental loading.
Microsoft SQL Server 7.0 Indexing Enhancements
An architectural enhancement to SQL Server 7.0 nonclustered indexes reduces nonclustered index maintenance in SQL Server 7.0. The advantage of having clustering keys at the leaf of the nonclustered index is that when a page split occurs in the clustered index, it will no longer require maintenance of the nonclustered indexes. This is a big improvement.
Smart read-ahead using intermediate index nodes is another performance improvement added to SQL Server 7.0. The intermediate index node is used as a data pump to issue async I/O requests for leaf pages.
Index Architecture
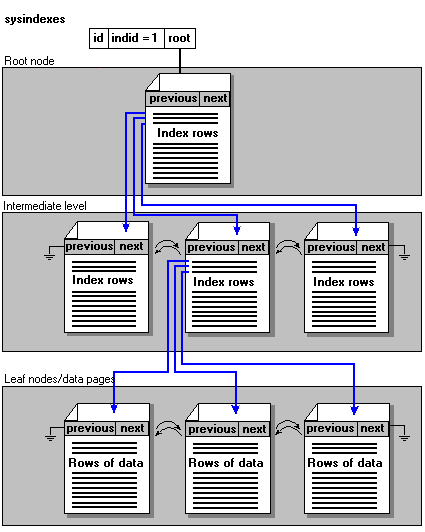
SQL Server indexes are organized as B-trees. Each page in an index holds a page header followed by index rows. Each index row contains a key value and a locator to either a page or a data row. The data row locator is an architectural difference in SQL Server 7.0.
Each page in an index is called an index node. The top node of the B-tree is called the root node. The bottom layer of nodes in the index are called the leaf nodes and are linked together in a doubly-linked list. In a clustered index, the data pages make up the leaf nodes. Any index levels between the root and the leaves are collectively known as intermediate levels.
The number of levels in a clustered index is determined by the number of rows in the table, the width of the data row, the width of the clustered key, and the page size. In SQL Server 7.0, the page size is 8 KB, four times larger than SQL Server 6.5 2-KB pages. The larger pages mean greater fanout, resulting in fewer index levels. In other words, given the larger page size, there are fewer data pages (more rows per page), and consequently fewer intermediate index entries.
Clustered Indexes
This illustration shows the structure of a clustered index.
Nonclustered Indexes
A nonclustered index is analogous to an index in a textbook. The data is stored in one place; the index is stored in another, with pointers to the storage location of the index items in the data. The lowest level, or leaf node, of a nonclustered index contains a locator to find the data row. In SQL Server 6.5, the locator is a row ID (RID) that points to the storage location (its page number and offset in the page) of the index entry. A RID is defined as the page and slot (row) number for the row. In SQL Server 7.0, the locator can be either a RID (if there is no clustered index) or the primary key of the clustered index. Therefore, a nonclustered index, in comparison with a clustered index, has an extra level between the index structure and the data itself.
This illustration shows the structure of nonclustered indexes.

The items in the index are stored in the order of the index values, but the information in the table is stored in a different order which can be dictated by a clustered index.
When Microsoft SQL Server searches for data based on a nonclustered index, it searches the index for the specified value to obtain the location of the rows of data, and then retrieves the data directly from their storage locations.
With SQL Server 6.5, the leaf level of nonclustered indexes uses a RID for each index entry that points to the data row. A RID is a page and slot (row) number for the row. When the nonclustered index is accessed, RIDs are used to quickly retrieve data rows.
In SQL Server 7.0, if there is a clustered index, the leaf level of all nonclustered indexes contains the clustering (primary) key. The primary key is used to locate the data row. If there is no clustered index, the leaf of the nonclustered index contains RIDs as pointers for each index entry.
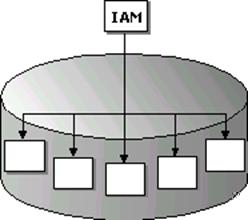
Heap Tables
Any table without a clustered index is called a heap structure. Heaps have one row in sysindexes with indid = 0. The column sysindexes.FirstIAM points to the first IAM page in the chain of IAM pages that manage the space allocated to the heap. Microsoft SQL Server 7.0 uses the IAM pages to navigate through the heap. The data pages and the rows within them are not in any specific order, and are not linked together. The only logical connection between data pages is that recorded in the IAM pages.
This illustration shows the structure of a heap table.
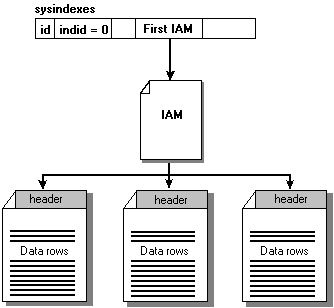
Table scans or serial reads of a heap are performed by scanning the IAMs to find the extents that hold pages for the heap. Because the IAM represents extents in the same order they exist in the file, serial heap scans progress uniformly down the file (for example, in disk order). A table scan on a heap works as follows:
1. SQL Server reads the first IAM on the first filegroup and scans all the extents on that IAM.
2. SQL Server repeats the process for each IAM for the heap in the file.
3. SQL Server repeats steps 1 and 2 for each file in the database or filegroup until the last IAM for the heap has been processed.
This is more efficient than the data page chains in earlier versions of SQL Server in which the data page chain often took a somewhat random path through the files of a database.
Index and Performance Issues in SQL Server 6.5
A problem with DSS-type activity (reading large portions of a table) in SQL Server 6.5 is that I/O follows the doubly linked list to read all pages in the table. SQL Server 6.5 link list-oriented I/O is most efficient when the data is stored contiguously. If the link list is discontiguous, SQL Server 6.5 table scans or nonclustered index scans are quite inefficient.
This illustration shows a doubly linked list.

Retrieving discontiguous pages in link list order requires disk arm movement. The worst case scenario is that link list pages are scattered all over various disk devices, adversely affecting I/O subsystem performance.
An object’s link list is formed from the header of each page. The header contains the current page number, previous page number, and next page number. This allows link list-oriented I/O to follow the link list in either direction.
When a table has indexes, order is imposed on the table (clustered) and index structure. When there is insufficient room on an index page for a row to be inserted in its proper order, a page split occurs: half of the rows on the target page move to a new page. This leaves room for the row that caused the split to be inserted.
The problem with page splits is index maintenance. Page splits always require all SQL Server 6.5 nonclustered indexes to update RIDS for rows that move to a new page. The combination of indexes and random inserts can present significant performance issues in SQL Server 6.5. Random inserts and page splits are especially problematic when the table has both clustered and nonclustered indexes.
Although page splits can occur at any index level, they are especially common at the leaf of the clustered index. The physical order of the data rows is determined by the clustered key. The reason splits are more common at the leaf of the clustered index has to do with the length of the data row. The combination of random inserts and wide data rows determines how often page splits occur.
Nonclustered indexes in SQL Server 6.5 contain RIDS that point to the row at the leaf of the clustered index. Consequently, a page split in SQL Server 6.5 affects not only the row inserted, but also the rows that have moved to a new page.
When a page split occurs, the link list is updated to reflect the new page. Table scans in SQL Server 6.5 follow the link list, which, in the case of random inserts, can be increasingly discontiguous over time.
The number of clustered index levels depends on the width of the clustered key, the width of the data rows, and the number of data rows. The number of data rows is included because the leaf of a clustered index is the data row. In the case of a nonclustered index, the number of levels depends only on the width of the nonclustered key and the number of data rows.
Consider the effect in DSS in which large I/O is the norm. Quite often, DSS workloads perform scans of either the clustered or nonclustered indexes. The result of a discontiguous link list is that physical I/O will require arm positioning to locate the leaf pages in link list order. Although read ahead can offer some relief, link list-oriented I/O is expensive.
Further, to correct a discontiguous link list in SQL Server 6.5, you can drop and re-create indexes, use DBCC DBREINDEX, or bulk copy the data out and in. Again, intermingled extents from other tables may limit the desired continguous effect.
All nonclustered indexes are rebuilt automatically by SQL Server 6.5 when the clustered index is rebuilt, because the leaf of the nonclustered index is a RID pointing to the data row. Rebuilding the clustered index will change the RID values for the data rows.
Major problem areas in SQL Server 6.5 are index maintenance due to page splits and (discontiguous) link list order I/O. Examples of link list order I/O include such wide ranging operations as table scans, range retrievals (between 1 and 100), DBCCs, and update statistics. The link list order I/O applies to both data pages and nonclustered leaf pages.
Index and Performance Issues in SQL Server 7.0
A change in SQL Server 7.0 nonclustered index architecture resolves the problem of nonclustered index maintenance due to clustered index page splits. Recall that a page split may move half the rows on a page to a new page to make room for an insert. The insert must take place in order of key value.
Page splits are especially problematic in SQL Server 6.5 if inserted primary key values are random. SQL Server 7.0 nonclustered index leaf levels now use the primary key of the clustered index (including a unique identifier, if necessary) to allow the data row to be located. Thus, a page split in the clustered index still moves half the rows to a new page, but the clustered key value does not change. Hence, there is no maintenance required in the nonclustered leaf.
When the clustered index is dropped in SQL Server 7.0, thereby removing the clustered key, all the nonclustered indexes are automatically rebuilt. The clustered key was used previously by the nonclustered index to locate the data rows, but now RIDS will be used.
You can drop the clustered index to move a table or to clean up discontiguous link lists due to page splits. Assuming you want to immediately re-create the clustered index, you do not want the nonclustered indexes to be automatically rebuilt. By adding the DROP EXISTING keyword to the CREATE CLUSTERED INDEX statement in SQL Server 7.0, you can drop and re-create the clustered index in one step without the automatic recreation of nonclustered indexes.
As a corollary, if a table does not have a clustered index, the nonclustered indexes revert to the RID architecture. However, it is important to know that page splits will not occur in the heap or data pages because there is no clustered index to impose ordering requirements.
In the case of heaps (no clustered index), SQL Server 6.5 and SQL Server 7.0 behave similarly with a few notable exceptions. First, page links (for example, previous page and next page) are not maintained for heaps in SQL Server 7.0. Unlike SQL Server 6.5, table scan operations and range operations will not perform link list order I/O in SQL Server 7.0. Instead, SQL Server 7.0 uses the index allocation map (IAM) to perform a disk order scan. Disk order sequential scan operations are an important advance that enables SQL Server 7.0 to operate at near disk speed.
Second, SQL Server 6.5 will not reuse empty space in a heap. Empty space is created when rows are deleted. Additionally, you may get empty space when a variable length row is updated, resulting in a row length larger than the original. If the longer row will not fit on the same page, SQL Server 6.5 will move it to the last page in the heap. SQL Server 6.5 will always insert at the end of the heap link.
In contrast, SQL Server 7.0 first checks for available space in existing pages by using Percent Free Space (PFS) pages. PFS pages record whether an individual page has been allocated, and the amount of space free on each page. Each PFS page covers 8,000 pages. For each page, the PFS has a bitmap recording whether the page is empty, 1-to-50-percent full, 51-to-80-percent full, 81-to-95-percent full, or 96-to-100-percent full.
After an extent has been allocated to an object, SQL Server uses the PFS pages to record which pages in the extent are allocated or free, and how much free space is available for use. This information is used when SQL Server has to allocate a new page, or when it needs to find a page with free space available to hold a newly inserted row.
A PFS page is the first page after the file header page in a data file (with page number 1). Next comes a Global Allocation Map (GAM). GAM pages record what extents have been allocated. Each GAM covers 64,000 extents, or nearly 4 GB of data. The GAM has one bit for each extent in the interval it covers. If the bit is 1, the extent is free; if the bit is 0, the extent is allocated.
Secondary Global Allocation Map (SGAM) pages record what extents are currently used as mixed extents and have at least one unused page. Each SGAM covers 64,000 extents, or almost 4 GB of data. The SGAM has one bit for each extent in the interval it covers. If the bit is 1, the extent is being used as a mixed extent and has free pages; if the bit is 0, the extent is not being used as a mixed extent, or it is a mixed extent whose pages are all in use.
This illustration shows the managing of extent allocations in SQL Server 7.0 with PFS, GAM, SGAM.

Additional PFS pages follow the first in 8,000 page increments. Additional GAM pages follow the first GAM (on page 2) page in 64,000 page increments. Additional SGAM pages follow the first SGAM (on page 3) page in 64,000 page increments. In conclusion, SQL Server 7.0 conserves space through reuse of empty space in heaps. Table scans are more efficient with better space utilization.
Link lists are not maintained for heap tables in SQL Server 7.0. The implication is that table scans will not use link list-oriented I/O to perform a table scan. Instead, SQL Server 7.0 performs sequential disk order scans using an IAM. The IAM identifies all extents owned by that object and allows sequential disk order scan operations. A single IAM can represent disk sizes up to 4 GB. This allows near disk speed operations in SQL Server 7.0 and is a vast improvement over SQL Server 6.5 link list-oriented I/O for scan operations.
Parallel scans can be performed on unordered index scans of the leaf or on heap tables that span multiple files. In the case of a clustered index or a covered query (nonclustered leaf scan), SQL Server 7.0 performs parallel sequential disk scans using the IAM. Stored in sysindexes, there is an IAM entry for each index and disk combination.
In addition to disk order scans, SQL Server 7.0 indexing includes other features specific to DSS. Smart read-ahead techniques use the intermediate node and index to act as a data pump in issuing asynch I/O requests. The intermediate node contains a list of pages in the next level and assists in issuing I/O reads for leaf pages.
This illustration shows smart read-ahead with indexes.
From a consistency standpoint, latches are used for intermediate index levels instead of locks in SQL Server 7.0. Latches are lightweight and efficient (approximately one-fourth the cost of a lock) and do not consume memory resources.
Index Creation in SQL Server 7.0
Because clustering keys are included in the leaf level of nonclustered indexes, it is important that the clustered index be as short as possible. Thus, numeric, integer, smallint, tinyint, money, datetime, smalldatetime, and short varchars (and short chars) should be used. If the clustered index is not unique, a uniqueidentifier is created by SQL Server for uniqueness.
Create index operations in SQL Server 7.0 are faster than they were in SQL Server 6.5. The time it takes to create an index depends on factors such as the number of columns in the index, the width of the columns, and the number of index entries. For each column, there is a compare operation to examine the column value.
During index creation, there are two phases: data sorting according to key value, and merging, which is I/O intensive.
If the I/O subsystem is efficient, the CPU will be highly utilized. As stated previously, a highly utilized CPU is the objective, because the capacity of the CPU is the absolute fixed resource. For single CPU systems, indexes must be created in a serial fashion. On multiple CPU systems, multiple simultaneous indexes can be created.
Parallel Index Creation in SQL Server 7.0
The first index created should be the clustered index because the clustered index sorts the data rows. After the clustered index is created for a table, its nonclustered indexes can be created in parallel.
A general rule for minimizing index creation time is to rank elapsed index creation times in descending order. Assign (in descending order) the create index operations to run in a round-robin fashion across available CPUs. The number of concurrent creates should not exceed the number of CPUs.
Drafting is a performance factor to consider when creating indexes. If the multiple create index operations are running concurrently, they can share the base table pages that are read in. This is referred to as drafting, like a speed skater catching the draft of the leader. Assuming the indexes are of similar size, a drafting effect occurs when the lead thread (SPID) physically reads in the table pages. Other threads reuse pages in cache: in this case, the I/O is logical, not physical.
If create index operations vary in number of columns and width, the drafting effect can be lost as the second index create falls farther and farther behind. As previously stated, the width and number columns are factors that determine the speed of the index creation. If the second index falls too far behind (given the size of the cache), both the first and second index creation will require physical I/O and the drafting effect is lost. Thus, instead of a single table scan (with drafting), multiple physical scans of the base table can occur.
Index Tuning Wizard
The correct selection of indexes is vital for good performance. Because indexes provide an alternative method to access data, your Transact-SQL syntax plays a critical role in the process of index selection. The trade-offs are simple. The benefit is faster access to locate rows (such as SELECT statement). The cost of an index is measured by index maintenance (for inserts, updates, and deletes) and additional space usage.
SQL Server 7.0 provides the SQL Server Index Tuning Wizard to evaluate these trade-offs and propose the optimum indexes for your query volume. The SQL Server Profiler can be used to capture Transact-SQL statements.
The Transact-SQL statements that represent user volume and your database design are used by the Index Tuning Wizard to determine the optimum index implementation. It compares the benefit of index access versus the cost of index maintenance. The Index Tuning Wizard also compares different indexing schemes to arrive at the optimal index configuration.
Thus, the Index Tuning Wizard, using a series of algorithms to compare benefits and costs of indexing schemes, determines a list of clustered and nonclustered indexes that are well-suited for your Transact-SQL statements and database design.
OLTP environments are characterized by a large number of transactions involving small amounts of data. In contrast, decision support workloads typically retrieve large amounts of data with a small number of transactions. These distinctions are important to note because the efficient data retrieval techniques for OLTP are not necessarily optimal for DSS.
Query Optimizer
The query optimizer selects the best or most efficient method to get your data. The result of this selection process is called a query plan. A query plan is a series of steps that Microsoft SQL Server will go through to retrieve, process, and present your requested information.
Prior to execution, the query optimizer selects a query plan from among the various alternative strategies (data access techniques and steps) that can be used to satisfy the query. Each alternative strategy is assigned an anticipated cost. Examples of alternative strategies include the use of indexes or table scans, worktables, join orders, sorts, and so on. The optimizer then selects the lowest cost strategy or plan as the query plan.
The cost is based on estimates (number of I/O operations, CPU seconds, memory, and so on) for executing a particular plan. It estimates these costs by keeping statistics about the number and composition of records in a table or index. Both SQL Server 6.5 and SQL Server 7.0 use cost as a basis for query plan selection.
Limitations of the SQL Server 6.5 Query Optimizer
Earlier versions of SQL Server provided limited ways of optimizing queries. For example, SQL Server 6.5 supported only one method for performing a join: nested loop iteration. The strategies used by the SQL Server 6.5 query processor include naïve and index nested loops algorithms for joins and an index nested loops grouping strategy. Although these algorithms are generally suitable for OLTP queries that navigate from record to record (for example, sorted data using indexes) through the database, they do not effectively handle the large unsorted inputs often required for DSS.
SQL Server 6.5 is geared for OLTP operations and works well with sorted data, for example indexes. Although SQL Server 6.5 nested loop iteration joins work well with sorted (indexed) data, they are often inefficient with unsorted data or where there is no suitable index.
In certain instances, SQL Server 6.5 will create an index where none exists, just to run the query. This is because the optimizer believes that creating a temporary index is cheaper than doing table scans. The temporary index is discarded when the query is completed. Query plans that contain a reformatting step illustrate this point.
Creating a temporary index (reformatting) is sometimes undesirable but unavoidable in SQL Server 6.5 unless a permanent index is created. Because indexes result in maintenance overhead and additional space consumption, it is not necessarily an automatic decision to add indexes to avoid reformatting.
Goals of the SQL Server 7.0 Query Optimizer
SQL Server 7.0 offers considerable improvements in the sophistication of the query optimizer. The goal of SQL Server 7.0 is three-fold:
· To provide top-end scalability using parallel queries and utilities.
· To provide the most efficient sequentially executed operations possible.
· To combine efficient sequential operations into parallel plans when warranted.
Toward this end, SQL Server 7.0 adds intraquery parallelism, hash join, and merge join, which give the optimizer more options to choose from and are the algorithms of choice for many large queries. Parallelism provides high-end scalability. Hash and merge joins provide fast and efficient matching for the large unsorted inputs common to DSS.
The new optimization strategies or algorithms in SQL Server 7.0 include:
· Hash join.
· Sort merge join.
· Hash aggregation.
· Star schema optimizations.
· Parallel query.
· Union views for partitioned queries.
· Distributed query.
Parallel Queries
SQL Server 7.0 introduces intraquery parallelism, the ability to break a single query into multiple subtasks and distribute them across multiple processors in a symmetric multiprocessing (SMP) computer for execution. The SMP parallel query support in SQL Server 7.0 is an important enhancement for scalability.
The architecture uses a generic parallelization operation, one that creates multiple, parallel operations on the fly. Each operation (scan, sort, or join) does not know about parallelization. The advantage to this architecture is that all operations can be equally parallel. Also, the amount of parallelization does not depend on the particular function in question.
The parallel operator allows SQL Server 7.0 to add new operators easily, resulting in “parallel everything.” Scans, sorts, joins, and GROUP BY operations are done in parallel.
Query time is reduced when CPU resources are used in parallel rather than serially. In the case of a serial query, a single stream of pages is presented to subsequent operations. In the case of a parallel query, the pages are presented in multiple streams that enable parallel use of memory and CPU resources. The benefits of parallelism are especially evident in DSS queries and during batch processing.
Although the total cost of a SQL Server 7.0 parallel query plan may be greater than its serial equivalent, the objective of scalability and shorter query time is met through the balanced use of resources. Performance can be improved in such areas as batch processing. A SQL Server 6.5 serial plan during a batch cycle keeps a single CPU busy while the others are dormant. A SQL Server 7.0 parallel plan makes use of multiple CPUs and parallel I/O. Thus, SQL Server 7.0 parallelism balances system resource utilization.
Consequently, parallel queries run in less elapsed time by more fully using CPU and I/O bandwidth. This is the divide and conquer approach, applied to query execution.
Intraquery parallelism offers two benefits by reducing elapsed time for the query and dividing CPU time among multiple CPUs. However, the costs are an increased total effort for the query in terms of management issues with multiple threads including initialization (startup and tear down), synchronization, and interference.
The SQL Server 7.0 query optimizer looks at system usage as well as the query in determining the appropriate query plan. If the projected query cost is under the threshold (sp_configuration option) or the system is too busy, a serial plan will be generated (or a cached plan will be reused).
If the computer is an SMP computer, the system is not too busy, and the query cost is substantial, the SQL Server 7.0 query optimizer produces a parallel plan. If at execution time the system is too busy, SQL Server 7.0 generates a sequential plan and executes that one. Two plans (serial and parallel) may be produced for one query, but usually only one is produced.
SQL Server 7.0 execution differs from SQL Server 6.5 in that SQL Server 7.0 first tries to reduce query time by maximizing the use of system resources (for example, parallel CPU and I/O). However, if parallelism is not possible or not desirable, SQL Server 7.0 executes the lowest cost sequential plan, whereas SQL Server 6.5 automatically chooses and executes the least cost sequential query plan.
Hashing
The hashing strategies, new to SQL Server 7.0, provide for efficient handling of large unsorted data, joins, and worktables. These additional strategies give the query optimizer more choices that can benefit large queries.
The query execution engine in Microsoft SQL Server 7.0, in addition to supporting heterogeneous queries and exploiting parallel query evaluation as well as sophisticated index techniques, employs hash-based algorithms for inner and outer joins, semi-joins, set operations (such as intersection), grouping, duplicate removal, and caching results of expensive functions.
Joins and groupings are frequently used operations in relational query processing. Nonetheless, previous releases of SQL Server used only naïve and index nested loops algorithms for joins and an index nested loops grouping strategy. Although these algorithms are suitable for queries that navigate from record to record through the database, faster algorithms for large input sets were very important among the goals for Microsoft SQL Server 7.0.
Moreover, if fast set matching algorithms are available, some query plans may become attractive that have not been considered in the past. Therefore, the SQL Server 7.0 query optimizer considers index intersection, union, and difference, as well as joining two indexes of a single table on a common unique column (for example, the record identifier of the base file) to extend the concept of a covering index (also called index-only retrieval) from a single index to multiple indexes.
Hashing avoids sorts by using hash algorithms. Consequently, hashing techniques can result in substantial improvements in query performance. In contrast, SQL Server 6.5 often created sorted worktables when indexes were unavailable.
Union Views for Partitioned Queries
Constraints can provide useful information to the SQL Server 7.0 query optimizer. When used with a union view, a constraint can help the query optimizer estimate, and in some cases, enable the query optimizer to disregard tables that do not apply to the query. This is an example of a union view:
CREATE VIEW Sales_View
AS
SELECT * FROM Q1_tbl
UNION
SELECT * FROM Q2_tbl
UNION
SELECT * FROM Q3_tbl
UNION
SELECT * FROM Q4_tbl
Suppose there is a constraint on month where month is between 1 and 3 for Q1_tbl. Q2_tbl would have a month constraint of month between 4 and 6. Q3_tbl would have a month constrain between 7 and 9. Q4_tbl would have a month constraint between 10 and 12.
The constraints allow the following example to focus only on Q2_tbl. The other tables in the view are ignored.
SELECT * FROM Sales_view
WHERE month = 5
SQL Server detects all empty results when a constraint contradicts the selection criteria. This allows the query optimizer to ignore tables Q1_tbl, Q3_tbl, and Q4_tbl when a plan is generated. Even if the administrator has not declared a view, if the selection criteria are at odds with the constraint, the query optimizer recognizes this and generates an appropriate plan.
SQL Server 6.5 Statistics and Index Selection
The query optimizer in SQL Server uses statistics to estimate the number of rows that qualify for a given query. This estimate provides a basis for costing. When the data in an indexed column changes, statistics can become out of date and cause the query optimizer to make less-than-optimal decisions on how to process a query.
For example, if you create a table with an indexed column, load 1,000 rows of data, and ensure that each row has a unique value in the indexed column, the optimizer considers the indexed column a good way to collect the data for a query. If the values or distribution of an indexed column changes significantly due to a massive update or batch insert, a bad row estimation can result if statistics have not been updated to reflect the changes.
Updating statistics in SQL Server 6.5 is I/O-intensive because the entire table is scanned. Usually, this is scheduled during batch operations for very large tables.
In SQL Server 6.5 read ahead (RA) is based on heuristics. It is turned on and off based on configured RA hit and miss rates. Consequently, RA is not specified in the query plan.
SQL Server 7.0 Optimization
Optimization alternatives include the consideration of available indexes, search arguments, row estimates, I/O, and a host of other factors. A major factor is the determination of row estimates prior to execution. Row estimates are based on accurate statistics. Large row estimates can result in SQL Server 7.0 plans using parallel I/O or smart read-ahead techniques.
SQL Server automatically updates this statistical information periodically as the data in the table changes. The sampling is random across data pages and is taken from the table or nonclustered index for the smallest index that contains the columns needed by the statistics. Automatic update of statistical information is determined by the volume of data in the index and the amount of changing data. For large tables, automatic statistical sampling can be completed in less than one second.
For example, the statistics for a table containing 10,000 rows may need updating when 1000 index values have changed because 1000 values represents a significant percentage of the table. However, for a table containing 10 million index entries, 1000 changing index values is less significant.
SQL Server 7.0 statistics are gathered by using statistical sampling techniques. Statistical sampling is quite accurate and its cost is minimal. Under some circumstances, statistical sampling can not accurately characterize the data in a table. You can control the percentage of data that is sampled during automatic statistics updates on a table-by-table basis by using the SAMPLE clause of the UPDATE STATISTICS statement. You can also tell SQL Server not to maintain statistics for a given column or index by using the sp_autostats system stored procedure.
Statistics on Nonindex Columns
SQL Server 7.0 allows statistics to be gathered for nonindex columns. Also known as hypothetical indexes, statistics on nonindex columns that frequently appear in a WHERE clause with search arguments can provide more accurate row estimations. Accurate row estimations mean better plan selection. This example gets statistics on the column region:
SELECT * FROM Customer
WHERE zipcode = 90100
AND region = “NorthEast”
SQL Server 7.0 Stored Procedures
A stored procedure is a way to precompile one or more Transact-SQL statements. Executing a stored procedure is more efficient than executing a Transact-SQL statement because SQL Server does not have to compile a stored procedure from scratch; it simply optimizes the stored query tree for the procedure.
SQL Server 7.0 retains execution plans even for statements that are not in a stored procedure. It uses an efficient algorithm to compare new Transact-SQL statements with the Transact-SQL statements of existing execution plans. If SQL Server 7.0 determines that a new Transact-SQL statement matches the Transact-SQL statement of an existing execution plan, it reuses the plan. This reduces the performance benefit of precompiling stored procedures into execution plans.
Unlike SQL Server 6.5, the stored procedure execution plan in SQL Server 7.0 is reentrant. To accomplish reentrance, the execution plan is comprised of two components: the static execution plan and the execution context. There is an execution context for every instance. Consequently, if multiple instances are executing simultaneously, there will be a single static execution plan and multiple instances of the execution context. The execution context is comprised of pointers, values, and stack for each user instance.
Stored with the query plan are plan dependencies, or factors determining the query plan. The plan dependencies are used to determine when a reoptimization should be performed if statistics are updated.
For example, when table statistics are recomputed automatically (using statistical sampling), any stored procedure query plan in cache that referenced the table now has obsolete statistics. The plan is reoptimized automatically if it is determined that the changes to the statistics are significant and exceed the dependency threshold. Reoptimization may yield a different plan. The reoptimization does not affect plans that are being executed at the time.
SQL Server Profiler, Tracing, and Query Performance
SQL Server Profiler provides a means to capture trace information. In addition, SQL Server Profiler allows you to see all executed statements, including statements inside stored procedures. Information such as CPU, I/O (reads and writes), and execution time is captured for each statement. Problem areas can be pinpointed easily for further analysis.
Transact-SQL statements captured by SQL Server Profiler can be replayed at any time. Intervals can be set to mimic expected SQL Server workloads.
Normalization, Deferred Name Resolution, and Compilation
When a procedure is created, the statements in the procedure are parsed or validated for syntactical accuracy. If a syntactical error is encountered in the procedure definition, an error is returned and the procedure is not created. If the statements are syntactically correct, they are converted to a form that can be executed quickly by the SQL Server query processor when the procedure is executed. This process is called normalization.
In SQL Server 6.5 name resolution happens when the stored procedure is created. This means the objects referenced must exist at compile time. In SQL Server 7.0, name resolution is deferred until execution.
When a SQL Server 7.0 procedure is executed, the query processor reads the normalized form of the procedure and validates that the names of the objects used by the procedure are present. This process is called deferred name resolution because objects referenced by the stored procedure need not exist when the stored procedure is created, but only when it is executed.
SQL Server also performs other validation activities in the resolution stage (for example, the validation of column data type compatibility with variables). If the objects referenced by the procedure are missing when the procedure is executed, or if other errors are found in the resolution stage, an error is returned and the procedure does not execute.
Distributed Queries
SQL Server 7.0 can perform distributed queries, which are queries that involve data from two or more servers. SQL Server supports all retrievals, updates, and cursors, as well as transactions across nodes using the Microsoft Distributed Transaction Coordinator (DTC). SQL Server also maintains security across servers.
If any remote servers support indexes or Transact-SQL queries, the SQL Server query optimizer determines the largest possible query that can be sent to each remote server. The idea is to handle as much processing as remotely possible to reduce network traffic and overall query time.
In other words, the query optimizer assigns the maximum possible data reduction to each remote server. For example, if a remote query is issued against a one-million row table with a WHERE clause or an aggregation that returns only 10 records, the one million rows are processed at the remote server and only 10 records are sent across the network.
One issue with distributed queries is sort orders. In the example above, if a join is performed locally, the result is returned to SQL Server 7.0 for a final join with a SQL Server 7.0 table. However, differing sort orders cause another sort to take place before a final join can be done.
Heterogeneous Queries
Distributed queries may be heterogeneous, supporting any OLE DB or ODBC data source. On the SQL Server compact disc, there are OLE DB drivers for Oracle 7.x, Oracle 8.x, Microsoft Excel, Microsoft Access, dBASE, Paradox, and the Microsoft Visual FoxPro® database development system, as well as an OBDC gateway for other relational databases. OLE DB providers for other server databases (IBM DB2, SYBASE, and Informix) are available from third parties.
Distributed and heterogeneous queries allow coexistence with legacy applications and data, and extended data analysis. By keeping the data in its original data store, data redundancy and maintenance are also minimized.
Consider a four-table join using one SQL Server 7.0 table, one Access table, and two Oracle tables. Where possible, predicates and joins are pushed down to the remote server. Pushing the predicate or WHERE clause down remotely both restricts the result set, which is returned to SQL Server, and reduces network traffic.
For a single table in any heterogeneous data source, the result set (after applying the predicate) is returned to SQL Server 7.0 for a final join in SQL Server 7.0. In any query involving two or more tables on the same remote server, the joins occur remotely.
The on-going process of managing your DSS database includes backup, restore, incremental loads, and integrity issues.
Backup and Restore
During a Microsoft SQL Server 6.5 backup, transactions are delayed until pages are written, resulting in reduced transactional throughput. Disk is accessed in nonoptimal order, reducing performance by as much as 90 percent. Consequently, it is advisable to back up SQL Server 6.5 databases in a batch window.
Backup and restore operations have been greatly improved in SQL Server 7.0. Backups and restores operate at media speeds and scale well when more backup devices are added.
The fuzzy backup techniques used in SQL Server 7.0 cause minimal impact on running transactions. In fact, SQL Server 7.0 backups only reduce transactional throughput by 5 to 10 percent. For most customers, this means backups can run anytime.
SQL Server 7.0 backups use the Microsoft Tape Format. The fast backup capabilities of SQL Server 7.0 include database, filegroup or file backups. SQL Server 7.0 backup sets can be verified by doing a restore.
Database backups can be:
· Full.
· Differential.
· Transactional.
The notable addition in SQL Server 7.0 is the differential backup. The differential backup includes all changes since the last full database backup. Thus, to restore a database, the database backup and last differential backup are all that is required.
SQL Server 7.0 databases are re-created with a restore. Files are automatically relocated from the backup set.
For more information about backing up and restoring databases, see the SQL Server 7.0 white papers at www.microsoft.com/sql/.
Incremental Loading Techniques
A common task for DSS is incremental data loads. How do you easily load last month’s sales data? How do you keep 12 months of data rolling off the month’s data from a year ago? Union views of partitioned data provide an elegant way to deal with this common requirement.
To use union views of partitioned data, create a new table with the current period’s data. Place a constraint on the partitioning column (for example, Period_date). Add the new table to the union view. To roll off last year’s month, remove the old table from the union view.
The constraint allows SQL Server 7.0 to determine which tables are required based on the where clause. SQL Server 7.0 eliminates from consideration any table whose constraints violate the where clause.
For a full description of union views with partitioned data, see “Accessing the DSS Data” section in this document.
Integrity Issues
Database Consistency Checker (DBCC), used to verify the integrity of the database, checks database structures, link lists, and allocations. In SQL Server 6.5, DBCC integrity checking is essential but can be problematic. In SQL Server 7.0, DBCC integrity checking is optional.
DBCC performance in SQL Server 7.0 is improved by at least one order of magnitude (10X).
Checking SQL Server 6.5 Databases
DBCC operations in SQL Server 6.5 can be problematic for very large databases. SQL Server 6.5 DBCC operations use link list-oriented I/O techniques. This I/O strategy on discontiguous link lists results in long running, seek-intensive, disk arm movement. Consequently, multiple passes through the same disk could result.
In SQL Server 6.5, DBCC checkdb examines data integrity. DBCC NEWALLOC verifies allocation integrity. For very large databases, SQL Server 6.5 DBCC checking may not complete in the batch window.
Checking SQL Server 7.0 Databases
DBCC integrity checks in SQL Server 7.0 are much faster than they were in SQL Server 6.5. The disk order nature of SQL Server 7.0 DBCC scan operations results in near disk speed performance. Parallel scans are done on each file. In SQL Server 7.0, DBCC checkdb examines both data and allocation integrity.
DBCC checking in SQL Server 7.0 is optional. Run-time validation in SQL Server 7.0 detects many problems immediately. Simpler data structures and more robust algorithms provide solid database integrity.
SQL Server 7.0 DBCC checkdb performs the equivalent of SQL Server 6.5 checkdb and NEWALLOC. You can verify individual filegroups with DBCC CHECKFILEGROUP. Less frequent checks on read-only, infrequently modified, or less critical data can further shorten the batch window.
Microsoft SQL Server 7.0 has been redesigned for the enterprise. It sets the quality standard by which all databases will be measured in terms of scalability, high performance, and ease of use.
The revamped storage engine and new optimization techniques of SQL Server 7.0 scale to meet the rigorous resource requirements of large DSS databases. These improvements provide new capabilities for all types of workloads.
Changes to the storage engine architecture, query processor, and resource management provide high scalability and significant performance gains through the efficient usage of I/O and CPU resources. In combination, these changes produce near disk and channel speed performance for such wide-ranging activities as table scans, database loads, and backups.
Industry-leading ease-of-use features range from dynamic resource management to auto-shrink file storage. Including 27 wizards, SQL Server 7.0 is unparalleled in maximizing the efficiency of administrative resources.